#memory utilization

Oak0.2 Release: Significant Improvements to Throughput, Memory Utilization, and User Interface
ByAnastasia Braginsky, Sr. Research Scientist, Verizon Media Israel

Creating an open source software is an ongoing and exciting process. Recently, Oak open-source library delivered a new release: Oak0.2, which summarizes a year of collaboration. Oak0.2 makes significant improvements in throughput, memory utilization, and user interface.
OakMap is a highly scalable Key-Value Map that keeps all keys and values off-heap. The Oak project is designed for Big Data real-time analytics. Moving data off-heap, enables working with huge memory sizes (above 100GB) while JVM is struggling to manage such heap sizes. OakMap implements the industry-standard Java8 ConcurrentNavigableMap API and more. It provides strong (atomic) semantics for read, write, and read-modify-write, as well as (non-atomic) range query (scan) operations, both forward and backward. OakMap is optimized for big keys and values, in particular, for incremental maintenance of objects (update in-place). It is faster and scales better with additional CPU cores than the popular Java’s ConcurrentNavigableMap implementationConcurrentSkipListMap.
Oak data is written to the off-heap buffers, thus needs to be serialized (converting an object in memory into a stream of bytes). For retrieval, data might be deserialized (object created from the stream of bytes). In addition, to save the cycles spent on deserialization, we allow reading/updating the data directly via OakBuffers. Oak provides this functionality under the ZeroCopy API.
If you aren’t already familiar with Oak, this is an excellent starting point to use it! Check it out and let us know if you have any questions.
Oak keeps getting better: Introducing Oak0.2
We have made a ton of great improvements to Oak0.2, adding a new stream scanning for improved performance, releasing a ground-up rewrite of our Zero Copy API’s buffers to increase safety and performance, and decreasing the on-heap memory requirement to be less than 3% of the raw data! As an exciting bonus, this release also includes a new version of our off-heap memory management, eliminating memory fragmentation.
Below we dive deeper into sub-projects being part of the release.
Stream Data Faster
When scanned data is held by any on-heap data structures, each next-step is very easy: get to the next object and return it. To retrieve the data held off-heap, even when using Zero-Copy API, it is required to create a new OakBuffer object to be returned upon each next step. Scanning Big Data that way will create millions of ephemeral objects, possibly unnecessarily, since the application only accesses this object in a short and scoped time in the execution.
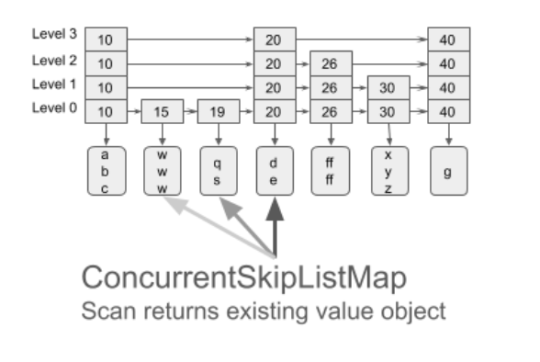

To avoid this issue, the user can use our new Stream Scan API, where the same OakBuffer object is reused to be redirected to different keys or values. This way only one element can be observed at a time. Stream view of the data is frequently used for flushing in-memory data to disk, copying, analytics search, etc.
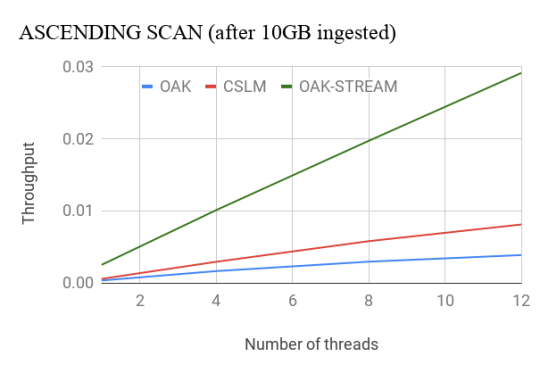
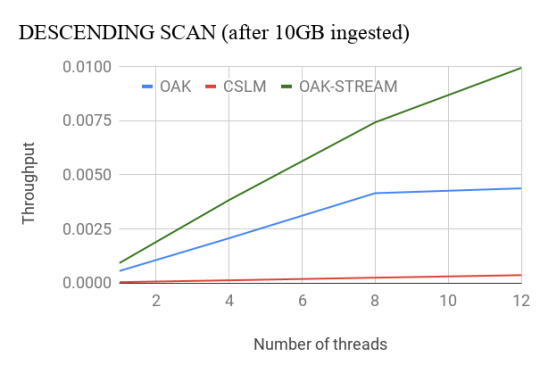
Oak’s Stream Scan API outperforms CSLM by nearly 4x for the ascending case. For the descending case, Oak outperforms CSLM by more than 8x even with less optimized non-stream API. With the Stream API, Oak’s throughput doubles. More details about the performance evaluation can be found here.
Safety or Performance? Both!
OakBuffers are core ZeroCopy API primitives. Previously, alongside with OakBuffers, OakMap exposed the underlying ByteBuffers directly to the user, for the performance. This could cause some data safety issues such as an erroneous reading of the wrong data, unintentional corrupting of the data, etc. We couldn’t choose between safety and performance, so strived to have both!
With Oak0.2, ByteBuffer is never exposed to the user. Users can choose to work either with OakBuffer which is safe or with OakUnsafeDirectBuffer which gives you faster access, but use it carefully. With OakUnsafeDirectBuffer, it is the user’s responsibility to synchronize and not to access deleted data, if the user is aware of those issues, OakUnsafeDirectBuffer is safe as well.
Our safe OakBuffer works with the same, great and known, OakMap performance, which wasn’t easy to achieve. However, if the user is interested in even superior speed of operations, any OakBuffer can be cast to OakUnsafeDirectBuffer.
Less (metadata) is more (data)
In the initial version of OakMap we had an object named handler that was a gateway to access any value. Handler was used for synchronization and memory management. Handler took about 256 bytes per each value and imposed dereferencing on each value access.
Handler is now replaced with an 8-bytes header located in the off-heap, next to the value. No dereferencing is needed. All information needed for synchronization and memory manager is kept there. In addition, to keep metadata even smaller, we eliminated the majority of the ephemeral object allocations that were used for internal calculations.
This means less memory is used for metadata and what was saved goes directly to keep more user data in the same memory budget. More than that, JVM GC has much less reasons to steal memory and CPU cycles, even when working with hundreds of GBs.

Fully Reusable Memory for Values
As explained above, 8-byte off-heap headers were introduced ahead of each value. The headers are used for memory reclamation and synchronization, and to hold lock data. As thread may hold the lock after a value is deleted, the header’s memory couldn’t be reused. Initially the header’s memory was abandoned, causing a memory leak.
The space allocated for value is exactly the value size, plus header size. Leaving the header not reclaimed, creates a memory “hole” where a new value of the same size can not fit in. As the values are usually of the same size, this was causing fragmentation. More memory was consumed leaving unused spaces behind.
We added a possibility to reuse the deleted headers for new values, by introducing a sophisticated memory management and locking mechanism. Therefore the new values can use the place of the old deleted value. With Oak0.2, the scenario of 50% puts and 50% deletes is running with a stable amount of memory and performs twice better than CSLM.
We look forward to growing the Oak community! We invite you to explore the project, use OakMap in your applications, raise issues, suggest improvements, and contribute code. If you have any questions, please feel free to send us a note. It would be great to hear from you!
Acknowledgements:
Liran Funaro,Eshcar Hilel,Eran Meir,Yoav Zuriel,Edward Bortnikov,Yonatan Gottesman