If you’ve ever applied for a job, you know about that tricky salary history question interviewers almost always ask.
Today New York City will officially ban employers from asking about pay history during hiring processes in order to address the city’s wage gap which keeps women and people of color from earning the same amount of money for the same amount of labor compared to white men.
Irecently finished reading mathematician Cathy O’Neil’s book, Weapons of Math Destruction, and learned that even if a question about pay history is entirely removed, interviewers can use questions about salary expectation as a proxy and that can still limit a minority’s chance to be paid fairly. Plus, with the help of third-party vendors and credit check companies who amass data on Americans all the time - selling our personal data - I wanted to learn more about how the law can prevent employers from taking advantage of applicants in our era of data collection and inequality.
So, I spoke with the First Lady of New York City, Chirlane McCray, along with the commissioner on NYC Commission on Human Rights, Carmelyn Malalis, and public advocate, Letitia James, who was the main person to introduce the legislation. Here’s the interview.
By Akshay Sarma, Principal Engineer, Verizon Media & Brian Xiao, Software Engineer, Verizon Media
This is the first of an ongoing series of blog posts sharing releases and announcements for Bullet, an open-sourced lightweight, scalable, pluggable, multi-tenant query system.
Bullet allows you to query any data flowing through a streaming system without having to store it first through its UI or API. The queries are injected into the running system and have minimal overhead. Running hundreds of queries generally fit into the overhead of just reading the streaming data. Bullet requires running an instance of its backend on your data. This backend runs on common stream processing frameworks (Storm and Spark Streaming currently supported).
The data on which Bullet sits determines what it is used for. For example, our team runs an instance of Bullet on user engagement data (~1M events/sec) to let developers find their own events to validate their code that produces this data. We also use this instance to interactively explore data, throw up quick dashboards to monitor live releases, count unique users, debug issues, and more.
Sinceopen sourcing Bullet in 2017, we’ve been hard at work adding many new features! We’ll highlight some of these here and continue sharing update posts for future releases.
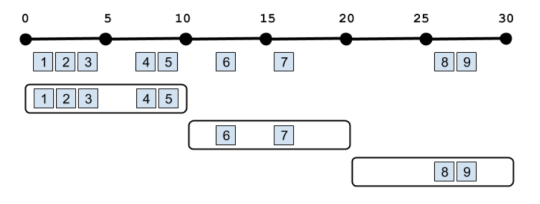
Windowing
Bullet used to operate in a request-response fashion - you would submit a query and wait for the query to meet its termination conditions (usually duration) before receiving results. For short-lived queries, say, a few seconds, this was fine. But as we started fielding more interactive and iterative queries, waiting even a minute for results became too cumbersome.
Enter windowing! Bullet now supports time and record-based windowing. With time windowing, you can break up your query into chunks of time over its duration and retrieve results for each chunk. For example, you can calculate the average of a field, and stream back results every second:
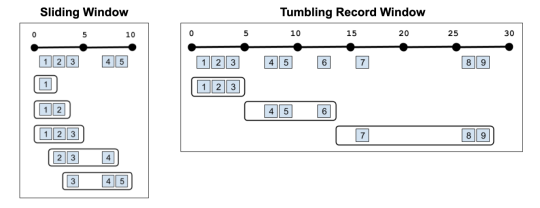
In the above example, the aggregation is operating on all the data since the beginning of the query, but you can also do aggregations on just the windows themselves. This is often called a Tumblingwindow:
With record windowing, you can get the intermediate aggregation for each record that matches your query (a Sliding window). Or you can do a Tumblingwindow on records rather than time. For example, you could get results back every three records:
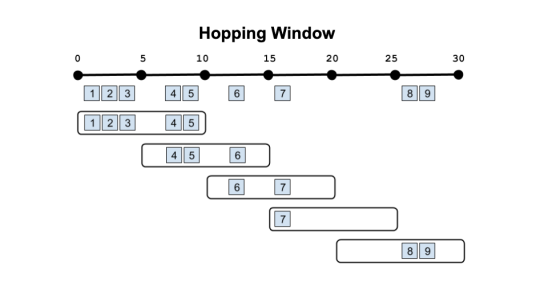
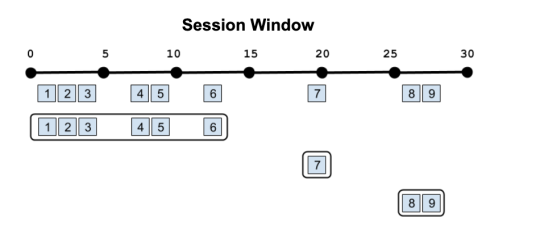
Overlapping windows in other ways (Hopping windows) or windows that reset based on different criteria (Session windows, Cascading windows) are currently being worked on. Stay tuned!
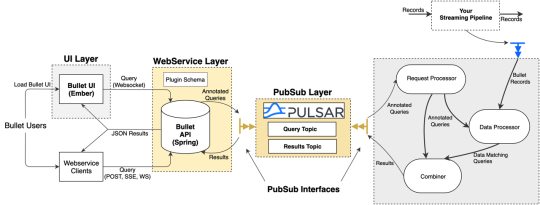
Apache Pulsar support as a native PubSub
Bullet uses a PubSub (publish-subscribe) message queue to send queries and results between the Web Service and Backend. As with everything else in Bullet, the PubSub is pluggable. You can use your favorite pubsub by implementing a few interfaces if you don’t want to use the ones we provide. Until now, we’ve maintained and supported a REST-based PubSub and an Apache Kafka PubSub. Now we are excited to announce supporting Apache Pulsar as well! Bullet Pulsar will be useful to those users who want to use Pulsar as their underlying messaging service.
If you aren’t familiar with Pulsar, setting up a local standalone is very simple, and by default, any Pulsar topics written to will automatically be created. Setting up an instance of Bullet with Pulsar instead of REST or Kafka is just as easy. You can refer to our documentation for more details.
Plug your data into Bullet without code
While Bullet worked on any data source located in any persistence layer, you still had to implement an interface to connect your data source to the Backend and convert it into a record container format that Bullet understands. For instance, your data might be located in Kafka and be in the Avro format. If you were using Bullet on Storm, you would perhaps write a Storm Spout to read from Kafka, deserialize, and convert the Avro data into the Bullet record format. This was the only interface in Bullet that required our customers to write their own code. Not anymore! Bullet DSL is a text/configuration-based format for users to plug in their data to the Bullet Backend without having to write a single line of code.
Bullet DSL abstracts away the two major components for plugging data into the Bullet Backend. A Connector piece to read from arbitrary data-sources and a Converter piece to convert that read data into the Bullet record container. We currently support and maintain a few of these - Kafka and Pulsar for Connectors and Avro, Maps and arbitrary Java POJOs for Converters. The Converters understand typed data and can even do a bit of minor ETL (Extract, Transform and Load) if you need to change your data around before feeding it into Bullet. As always, the DSL components are pluggable and you can write your own (and contribute it back!) if you need one that we don’t support.
We appreciate your feedback and contributions! Explore Bullet on GitHub, use and help contribute to the project, and chat with us on Google Groups. To get started, try our Quickstarts on SparkorStorm to set up an instance of Bullet on some fake data and play around with it.
By Michael Natkovich, Akshai Sarma, Nathan Speidel, Marcus Svedman, and Cat Utah
Big Data is no longer just Apache server logs. Nowadays, the data may be user engagement data, performance metrics, IoT (Internet of Things) data, or something else completely atypical. Regardless of the size of the data, or the type of querying patterns on it (exploratory, ad-hoc, periodic, long-term, etc.), everyone wants queries to be as fast as possible and cheap to run in terms of resources. Data can be broadly split into two kinds: the streaming (generally real-time) kind or the batched-up-over-a-time-interval (e.g., hourly or daily) kind. The batch version is typically easier to query since it is stored somewhere like a data warehouse that has nice SQL-like interfaces or an easy to use UI provided by tools such as Tableau, Looker, or Superset. Running arbitrary queries on streaming data quicklyandcheaply though, is generally much harder… until now. Today, we are pleased to share our newly open sourced, forward-looking general purpose query engine, called Bullet, with the community on GitHub.
With Bullet, you can:
Powerful and nested filtering
Fetching raw data records
Aggregating data using Group Bys (Sum, Count, Average, etc.), Count Distincts, Top Ks
Getting distributions of fields like Percentiles or Frequency histograms
One of the key differences between how Bullet queries data and the standard querying paradigm is that Bullet does not store any data. In most other systems where you have a persistence layer (including in-memory storage), you are doing a look-back when you query the layer. Instead, Bullet operates on data flowing through the system after the query is started – it’s a look-forward system that doesn’t need persistence. On a real-time data stream, this means that Bullet is querying data after the query is submitted. This also means that Bullet does not query any data that has already passed through the stream. The fact that Bullet does not rely on a persistence layer is exactly what makes it extremely lightweight and cheap to run.
To see why this is better for the kinds of use cases Bullet is meant for – such as quickly looking at some metric, checking some assumption, iterating on a query, checking the status of something right now, etc. – consider the following: if you had a 1000 queries in a traditional query system that operated on the same data, these query systems would most likely scan the data 1000 times each. By the very virtue of it being forward looking, 1000 queries in Bullet scan the data only once because the arrival of the query determines and fixes the data that it will see. Essentially, the data is coming to the queries instead of the queries being farmed out to where the data is. When the conditions of the query are satisfied (usually a time window or a number of events), the query terminates and returns you the result.
A Brief Architecture Overview
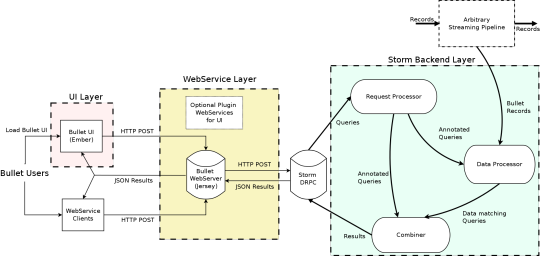
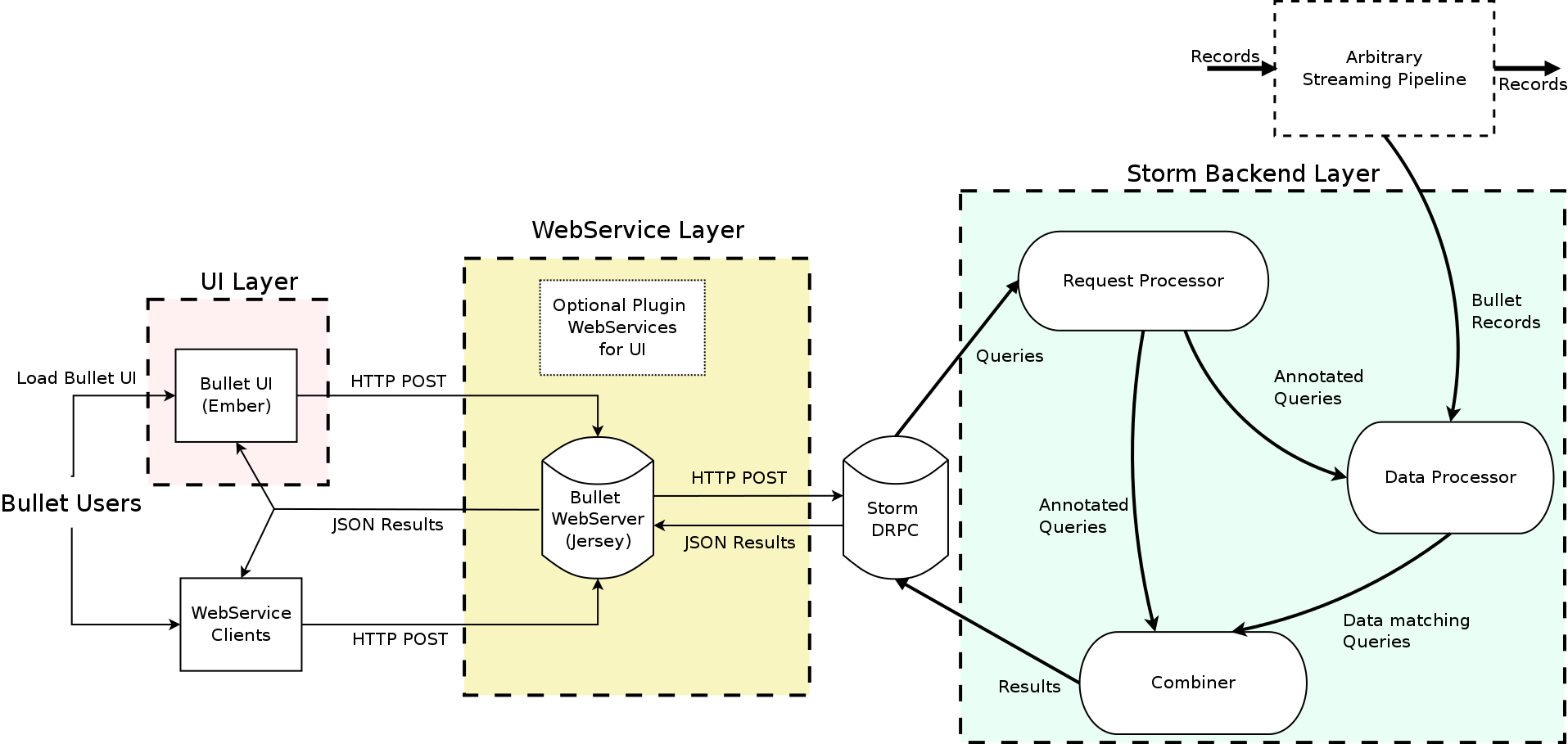
High Level Bullet Architecture
The Bullet architecture is multi-tenant, can scale linearly for more queries and/or more data, and has been tested to handle 700+ simultaneous queries on a data stream that had up to 1.5 million records per second, or 5-6 GB/s. Bullet is currently implemented on top of Storm and can be extended to support other stream processing engines as well, like Spark Streaming or Flink. Bullet is pluggable, so you can plug in any source of data that can be read in Storm by implementing a simple data container interface to let Bullet work with it.
The UI, web service, and the backend layers constitute your standard three-tier architecture. The Bullet backend can be split into three main subsystems:
Request Processor – receives queries, adds metadata, and sends it to the rest of the system
Data Processor – reads data from an input stream, converts it to a unified data format, and matches it against queries
Combiner – combines results for different queries, performs final aggregations, and returns results
The web service can be deployed on any servlet container, like Jetty. The UI is a Node-based Ember application that runs in the client browser. Our full documentation contains all the details on exactly how we perform computationally-intractable queries like Count Distincts on fields with cardinality in the millions, etc. (DataSketches).
Usage at Yahoo
An instance of Bullet is currently running at Yahoo in production against a small subset of Yahoo’s user engagement data stream. This data is roughly 100,000 records per second and is about 130 MB/s compressed. Bullet queries this with about 100 CPU Virtual Cores and 120 GB of RAM. This fits on less than 2 of our (64 Virtual Cores, 256 GB RAM each) test Storm cluster machines.
One of the most popular use cases at Yahoo is to use Bullet to manually validate the instrumentation of an app or web application. Instrumentation produces user engagement data like clicks, views, swipes, etc. Since this data powers everything we do from analytics to personalization to targeting, it is absolutely critical that the data is correct. The usage pattern is generally to:
Submit a Bullet query to obtain data associated with your mobile device or browser (filter on a cookie value or mobile device ID)
Open and use the application to generate the data while the Bullet query is running
Go back to Bullet and inspect the data
In addition, Bullet is also used programmatically in continuous delivery pipelines for functional testing instrumentation on product releases. Product usage is simulated, then data is generated and validated in seconds using Bullet. Bullet is orders of magnitude faster to use for this kind of validation and for general data exploration use cases, as opposed to waiting for the data to be available in Hive or other systems. The Bullet UI supports pivot tables and a multitude of charting options that may speed up analysis further compared to other querying options.
We also use Bullet to do a bunch of other interesting things, including instances where we dynamically compute cardinalities (using a Count Distinct Bullet query) of fields as a check to protect systems that can’t support extremely high cardinalities for fields like Druid.
What you do with Bullet is entirely determined by the data you put it on. If you put it on data that is essentially some set of performance metrics (data center statistics for example), you could be running a lot of queries that find the 95th and 99th percentile of a metric. If you put it on user engagement data, you could be validating instrumentation and mostly looking at raw data.
We hope you will find Bullet interesting and tell us how you use it. If you find something you want to change, improve, or fix, your contributions and ideas are always welcome! You can contact us here.
Machine learning and data mining are well established techniques in the world of IT and especially among web companies and startups. Spam detection, personalization and recommendations are just a few of the applications made possible by mining the huge quantity of data available nowadays. However, “big data” is not only about Volume, but also about Velocity (and Variety, 3V of big data).
The usual pipeline for modeling data (what “data scientists” do) involves taking a sample from production data, cleaning and preprocessing it to make it usable, training a model for the task at hand and finally deploying it to production. The final output of this process is a pipeline that needs to run periodically (and be maintained) in order to keep the model up to date. Hadoop and its ecosystem (e.g., Mahout) have proven to be an extremely successful platform to support this process at web scale.
For example, models for mail spam detection get outdated with time and need to be retrained with new data. New data (i.e., spam reports) comes in continuously and the model starts being outdated the moment it is deployed: all the new data is sitting without creating any value until the next model update. On the contrary, incorporating new data as soon as it arrives is what the “Velocity” in big data is about. In this case, Hadoop is not the ideal tool to cope with streams of fast changing data.
Distributed stream processing engines are emerging as the platform of choice to handle this use case. Examples of these platforms are Storm,S4, and recently Samza. These platforms join the scalability of distributed processing with the fast response of stream processing. Yahoo has already adopted Storm as a key technology for low-latency big data processing.
Alas, currently there is no common solution for mining big data streams, that is, for doing machine learning on streams on a distributed environment.
Enter SAMOA
SAMOA (Scalable Advanced Massive Online Analysis) is a framework for mining big data streams. As most of the big data ecosystem, it is written in Java. It features a pluggable architecture that allows it to run on several distributed stream processing engines such as Storm and S4. SAMOA includes distributed algorithms for the most common machine learning tasks such as classification and clustering. For a simple analogy, you can think of SAMOA as Mahout for streaming.
SAMOA is both a platform and a library. As a platform, it allows the algorithm developer to abstract from the underlying execution engine, and therefore reuse their code to run on different engines. It also allows to easily write plug-in modules to port SAMOA to different execution engines.
As a library, SAMOA contains state-of-the-art implementations of algorithms for distributed machine learning on streams. The first alpha release allows classification and clustering.
For classification, we implemented a Vertical Hoeffding Tree (VHT), a distributed streaming version of decision trees tailored for sparse data (e.g., text). For clustering, we included a distributed algorithm based on CluStream. The library also includes meta-algorithms such as bagging.
HOW DOES IT WORK?
An algorithm in SAMOA is represented by a series of nodes communicating via messages along streams that connect pairs of nodes (a graph). Borrowing the terminology from Storm, this is called a Topology. Each node in the Topology is a Processor that sends messages to a Stream. The user code that implements the algorithm resides inside a Processor. Figure 3 shows an example of a Processor joining two stream from two source Processors. Here is a code snippet to build such a topology in SAMOA.
TopologyBuilder builder; Processor sourceOne = new SourceProcessor(); builder.addProcessor(sourceOne); Stream streamOne = builder.createStream(sourceOne); Processor sourceTwo = new SourceProcessor(); builder.addProcessor(sourceTwo); Stream streamTwo = builder.createStream(sourceTwo); Processor join = new JoinProcessor(); builder.addProcessor(join).connectInputShuffle(streamOne).connectInputKey(streamTwo);
SWEET! HOW DO I GET STARTED?
1. Download SAMOA
git clone [email protected]:yahoo/samoa.git cd samoa mvn -Pstorm package
Forest CoverType contains the forest cover type for 30 x 30 meter cells obtained from US Forest Service (USFS) Region 2 Resource Information System (RIS) data. It contains 581,012 instances and 54 attributes, and it has been used in several papers on data stream classification.
For more information about SAMOA, see the README and the wiki on github, or post a question on the mailing list.
SAMOA is licensed under an Apache Software License v2.0. You are welcome to contribute to the project! SAMOA accepts contributions under an Apache style contributor license agreement.
Good luck! We hope you find SAMOA useful. We will continue developing the framework by adding new algorithms and platforms.
The fanfiction community is huge and growing. It’s an intricate network of authors, reviewers, and readers contributing to the creation of some form of contemporary culture.
At the University of Washington, we are a group of researchers studying the fanfiction community and exploring the informal learning taking place there.
We were particularly interested in authors who are user-favorites on Fanfiction.Net. When a user favorites an author, there are certain characteristics of the author that the user finds intriguing. It could be that the story is very interesting or the style of writing of the author fascinates the reader. We aim to find which authors have been favorited the most and what factors correlate with a user favoriting an author.
This blog post explores the connection between users (in a particular fandom) and the authors that they have favorited on FanFiction.net. We us a metric to measure this relationship and try to find out how it correlates to other factors such as:
Number of stories and chapters published by the authors
Number of reviews received for the published stories
Total number of words written by the author
Number of favorites received
In our analysis below, we have used the PageRank algorithm on authors in the “Game of Thrones” fandom on Fanfiction.net. Each author has at least one favorite author, and we have exploited this detail for our analysis.
Motivation
Both of us are huge Game of Thrones fans. The exciting season 8 finale and the massive popularity of GoT on social media motivated us to explore this fandom. Our current goal is to analyze authors that have been favorited by users, and which features might have earned them favorites in the GoT fandom on Fanfiction.net. This analysis can pave the way for building a recommendation engine for users on Fanfiction.net.
Dataset
Our dataset has been scraped from Fanfiction.net. For the analysis, we used two primary tables - Story and Author_favorites. The ‘Story’ table contains data about the stories - including but not limited to a unique story identifier, user id, fandom id, number of reviews, number of followers, and so on. The ‘Author_favorites’ table contains data about the users and their favorited authors. Because the data in these tables were humongous, we limited our scope to the Game of Thrones fandom. We used a cluster of the data by only retrieving the data that consisted of stories written in the “Game of Thrones” fandom.
The dataset we used was formed by combining the User Favorite table, Fandom table, and Stories table. This gave us a table consisting of User IDs and their Favorited Author IDs, both belonging to the Game of Thrones fandom on Fanfiction.net.
Method and Process
PageRank is a billion-dollar algorithm which made Google what it is. Whilst the most popular application of PageRank is web search, it can be exploited in other areas as well. The web is a gigantic graph interconnected by the web links. And PageRank assigns a score of importance by calculating the ‘inlinks’ to a website. In our case, we have considered the dataset of users and their favorited authors as a form of a graph: Many users favorite authors and these users could be authors themselves who have been favorited by other users. Hence, every author will have none, one or more users who favorite them. And thus we can assign a score of ‘connectedness’ to the authors by using PageRank.
A visual representation of the graph is shown below. The blue dot at the center represents a user and the yellow dots represent the favorited users as well as the favorited users who have favorited other favorited users! When there are no out-links, the graph stops traversing.
Fig 1. Network of a user (of highest pagerank) and his/her favorite authors. Blue dot represents the user with highest PageRank and yellow dots are favorited authors
This graph shows the ‘connectedness’ amongst fanfiction authors. Now we attempt to determine which characteristics (features) have a good correlation with the PageRank score that we obtained. In simple words, we try to find out how closely related the PageRank score is with characteristics such as ‘number of reviews’, ‘total words written by the author’ and so on. How can this be done?
A simple way to do this is through Linear Regression. In linear regression, we plot the features against a single response and try to explain the relationship through a straight line. We are conducting our regression analysis by using metrics which depict an author’s output (quantity):
Total words written by authors
Number of stories and chapters published by the author
And those depicting the recognition received (quality) by the author in the form of:
Number of reviews received
Number of times the author’s stories have been favorited
The intuition behind our analysis is to discern if there is any correlation between the PageRank scores which is obtained through network analysis and the above-mentioned metrics.
Findings and Results
PageRank Distribution
The histogram below shows the distribution of PageRank scores. As expected the histogram follows the Power Law which means a small number of items are having high page rank scores while the majority of items is concentrated towards minimum scores.
Due to the nature of our distribution, we decided to strip off all the authors having a score above 0.5, as clearly they are outliers and may not represent how the majority of the community behaves. In fact, there is a possibility of authors with high page rank scores skewing our results.
Regression Analysis
The graph below shows a plot of PageRank score against total words and the line denotes the amount of correlation between the two. A positive slope indicates a positive correlation. Please note that even a slight increase in the PageRank makes a big difference. We can safely discern that as the authors increase their output, their score improves.
The second metric we used to measure an author’s output is Story-Chapter product which is the number of stories multiplied by the number of chapters. The reasoning behind multiplying both is that author adopt different styles for structuring their content. One author may have a story with multiple chapters, another one may write multiple stories with one chapter each. The plot below depicts positive correlation yet again.
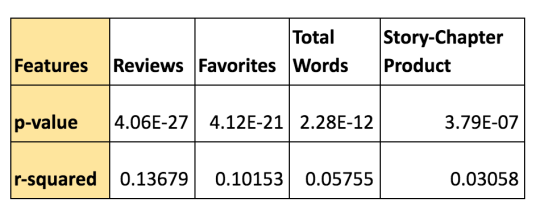
Running regression over other variables yields the following output:
Our initial assumptions were correct and the features we selected are all indicators of a good PageRank score. However, which one of these is the best predictor?
Enter p-value. P-value helps to determine the level of significance of our results. In statistics, a p-value <0.05 typically indicates the trend is statistically significant. P-value only helps to infer significance which means all the variables we included in our study are important predictors for the page rank score. What p-value does tell us is how important these variables. To know which feature is better predictor, we use another metric called r-square. R-square helps to know the degree of correlation between two expected output and the actual output. It is conceived in terms of percentage.
The p-values obtained for the above features are as follows:
Based on our analysis, it’s safe to conclude the number of reviews received by the author indicates a higher probability of that author being favorited often.
Conclusion
In our analysis, we used four features, two of which Total Words and Story-Chapter product indicate the output (quantity) of an author while the other two; the number of reviews received and number of times the author’s works have been favorited indicate the quality of an author’s work. These features have been plotted against the page rank score which indicates the degree of an author’s presence in the community. Through data science and statistical analysis, we were able to discern that the quality of works and feedback received by an author is a better indicator than the output.
Future Work
Our analysis can help pave the way for a recommendation engine for new users. This recommendation engine would leverage the PageRank algorithm to recommend authors to a user which he/she would most likely favorite. Just like Google and Amazon recommend products to users, our recommendation engine would suggest authors for users depending on the fandom they like. To build a recommendation engine as effective as Google or Amazon would require tons of optimization and fine-tuning, hence we have kept this as future work for this project.
As for fanfiction enthusiasts ourselves, we want to connect with the community so that they can help us in our analysis. Inputs from the community are always encouraged as this would help us make a better recommendation engine. So please comment on your views on the following questions:
What would you like to see recommended? We aim to recommend the Authors, but are open to suggestions!
What parameters do you think would affect the action of a user favoriting an author? Do you think it’s just the story or could it be the number of reviews, genre or style of writing? Comment below! Our analysis indicates the number of reviews, however, it will be interesting to see if our analysis is aligning with what the community thinks.
Losmacrodatos, también llamados datos masivos,inteligencia de datos,datos a gran escalaobig data (terminología en idioma inglés utilizada comúnmente) es un término que hace referencia a conjuntos de datos tan grandes y complejos como para que hagan falta aplicaciones informáticas no tradicionales de procesamiento de datos para tratarlos adecuadamente. Por ende, los procedimientos usados para encontrar patrones repetitivos dentro de esos datos son más sofisticados y requieren un software especializado.
The First-Person Industrial Complex by Laura Bennett The Internet prizes the harrowing personal essay. But sometimes telling your story comes with a price.
This is a key problem with the new first-person economy: the way it incentivizes knee-jerk, ideally topical self-exposure, the hot take’s more intimate sibling. The mandate at xoJane, according to Carroll, was: the more “shameless” an essay, the better. Carroll describes how “internally crushing” it became to watch her inbox get flooded every day with the darkest moments in strangers’ lives: “eating disorders, sexual assault, harassment, ‘My boyfriend’s a racist and I just realized it.’ ” After a while, Carroll said, the pitches began to sound as if they were all written in the same voice: “immature, sort of boastful.” Tolentino, who worked as an editor at the HairpinbeforeJezebel, characterizes the typical Jezebel pitch as the “microaggression personal essay” or “My bikini waxer looked at me funny and here’s what it says about women’s shame,” and the typical Hairpin pitch as “I just moved to the big city and had a beautiful coffee shop encounter, and here’s what it says about urban life.”
It’s harder than ever to weigh the ethics of publishing these pieces against the market forces that demand them, especially as new traffic analytics make it easy to write and edit with metrics in mind. “I’ve always loved unvarnished, almost performative, extemporaneous bloggy writing,” Gould says. “But now an editor will be like, can you take this trending topic and make it be about you?” Sarah Hepola, who edits Salon’s personal essays, says that the question “What am I doing to these writers?” is always in the back of her mind: “I try to warn them that their Internet trail will be ‘I was a BDSM person,’ and they did it for $150.” But editors’ best efforts aside, this is, more than anything, a labor problem—writers toiling at the whims of a system with hazardous working conditions that involve being paid next to nothing and guaranteed a lifetime of SEO infamy. The first-person boom, Tolentino says, has helped create “a situation in which writers feel like the best thing they have to offer is the worst thing that ever happened to them.”
I really enjoyed reading the reddit comments on this piece. /u/walker6168 criticized the article, writing, “I felt like the author didn’t want to go the extra mile. It doesn’t quite condemn the practice for being exploitative and taking advantage of people who have had terrible experiences. It doesn’t address the huge risk that comes with the format: verifying the story, like with the Rolling Stones UVA article. Nor does it really engage with the format’s desire to distort every tragedy into a politically correct format.” /u/smeethu countered, “I agree that the author didn’t go all the way and condemn the practice, but she still went into enough depth to make me explore its nuances. What I find is that these people are being exploited, but they are also exploiting themselves. If you are a starving freelance writer who is behind on rent, you know you need to get paid. Writing a shocking personal essay is one way to guarantee that. And it sells for the same reason people tune in to reality TV: we enjoy exploring the dark parts of our lives and it’s entertaining.” I feel like that argument is also used for other exploitive practices, like factories and sweatshops (i.e. the people who work there are happy to have found work at all). I think the way our society is structured encourages exploitation through commodification. We’re commodifying people’s experiences and are meant to feel okay about it because they’re supposed to speak to some universally relatable theme.
On a similar note, /u/DevFRus wrote, “At what point do such first-person essays stop being empowering and become a circus side-show? It seems to me like it is becoming less and less about giving people who had no voice before a voice, and more and more about exploiting those people for clicks. I wish the author engaged more critically with these aspects of the industry.” I think the question of when things stop being empowering is really important. It may feel empowering for someone to bare their heart in the moment, but does that mean true consent when the underlying system is exploitive? It may feel empowering for a woman to dress in provocative clothing, but is that truly making a statement in a culture steeped in compulsory sexuality and the sexual objectification of female bodies? When does the individual need to step back and consider the system rather than individual empowerment?
How big data is unfair by Moritz Hardt Understanding sources of unfairness in data driven decision making
As we’re on the cusp of using machine learning for rendering basically all kinds of consequential decisions about human beings in domains such as education, employment, advertising, health care and policing, it is important to understand why machine learning is not, by default, fair or just in any meaningful way.
This runs counter to the widespread misbelief that algorithmic decisions tend to be fair, because, y’know, math is about equations and not skin color. […] I’d like to refute the claim that “machine learning is fair by default”. I don’t mean to suggest that machine learning is inevitably unfair, but rather that there are powerful forces that can render decision making that depends on learning algorithms unfair.
[…] a learning algorithm is designed to pick up statistical patterns in training data. If the training data reflect existing social biases against a minority, the algorithm is likely to incorporate these biases. This can lead to less advantageous decisions for members of these minority groups. Some might object that the classifier couldn’t possibly be biased if nothing in the feature space speaks of the protected attributed, e.g., race. This argument is invalid. After all, the whole appeal of machine learning is that we can infer absent attributes from those that are present. Race and gender, for example, are typically redundantly encoded in any sufficiently rich feature space whether they are explicitly present or not. They are latent in the observed attributes and nothing prevents the learning algorithm from discovering these encodings. In fact, when the protected attribute is correlated with a particular classification outcome, this is precisely what we should expect. There is no principled way to tell at which point such a correlation is worrisome and in what cases it is acceptable.
My knee-jerk reaction when reading the article title was, “What? How can an algorithm be unfair?” It’s interesting to have forgotten about the inherent biases in the data itself.
Verge Fiction: The Date by Emily Yoshida The kid couldn’t have been older than 24, but there was a deep, distant fatigue to his face, and dark shadows lined his eyes. As he stared down at the tablet his face went slack, as if momentarily hypnotized by its glow. He took a sip of Red Bull Yellow Edition and handed the tablet back to me, this time with a new document labeled STUDY OUTLINE.
“So if you read through that, you’ll get the basic gist of it,” he said matter-of-factly. “Basically, you’re going to be contacted by a number of brands over the duration of the test period, and you’re to react as you normally would; you’re free to ignore them, or take advantage of whatever offers or promotions they have going on. Totally up to you. These may show up on email, Facebook, any social network you’ve provided us with — and as you’ll see in the release form in a second, you do get compensated more for every account you sign over to us. At the end of the study you’ll be asked to report how many brands contacted you, and we’ll check it against our own records. There is also a possibility that you will be a placebo subject — that no brands will contact you.”
[…] By the time I walked out the door I had had enough Pinot Grigio in me to feel sufficiently light on my feet about this whole adventure. All right, this is what you are doing now, I kept repeating in my head. You are in the world and you are letting yourself be changed by it, and that is normal and fun. The Jam Cellar was walking distance to my apartment, and as I made my way down there I listened to a playlist I had made for myself on Apple Music on my new fancy wireless headphones.
Every fifth step I felt my heart wobble a little as I remembered the picture of Marcus and that corgi. He had two other photos that I had stared at in between our chats — one of him sitting at a brunch spot drinking some kind of complicated looking cocktail out of a hammered copper mug, the other of him at the beach during sunset, in silhouette from behind as he ran toward the water. You couldn’t even see his face. He was willing to use a whole picture slot for something that didn’t even show his face. I liked that.
A terrifying, if a bit hokey, glimpse at the role of brands in our lives.
Creating an open source software is an ongoing and exciting process. Recently, Oak open-source library delivered a new release: Oak0.2, which summarizes a year of collaboration. Oak0.2 makes significant improvements in throughput, memory utilization, and user interface.
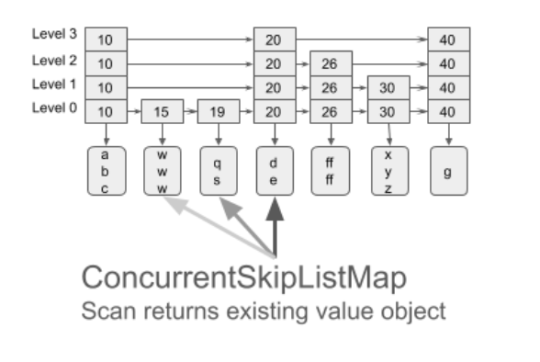
OakMap is a highly scalable Key-Value Map that keeps all keys and values off-heap. The Oak project is designed for Big Data real-time analytics. Moving data off-heap, enables working with huge memory sizes (above 100GB) while JVM is struggling to manage such heap sizes. OakMap implements the industry-standard Java8 ConcurrentNavigableMap API and more. It provides strong (atomic) semantics for read, write, and read-modify-write, as well as (non-atomic) range query (scan) operations, both forward and backward. OakMap is optimized for big keys and values, in particular, for incremental maintenance of objects (update in-place). It is faster and scales better with additional CPU cores than the popular Java’s ConcurrentNavigableMap implementationConcurrentSkipListMap.
Oak data is written to the off-heap buffers, thus needs to be serialized (converting an object in memory into a stream of bytes). For retrieval, data might be deserialized (object created from the stream of bytes). In addition, to save the cycles spent on deserialization, we allow reading/updating the data directly via OakBuffers. Oak provides this functionality under the ZeroCopy API.
If you aren’t already familiar with Oak, this is an excellent starting point to use it! Check it out and let us know if you have any questions.
Oak keeps getting better: Introducing Oak0.2
We have made a ton of great improvements to Oak0.2, adding a new stream scanning for improved performance, releasing a ground-up rewrite of our Zero Copy API’s buffers to increase safety and performance, and decreasing the on-heap memory requirement to be less than 3% of the raw data! As an exciting bonus, this release also includes a new version of our off-heap memory management, eliminating memory fragmentation.
Below we dive deeper into sub-projects being part of the release.
Stream Data Faster
When scanned data is held by any on-heap data structures, each next-step is very easy: get to the next object and return it. To retrieve the data held off-heap, even when using Zero-Copy API, it is required to create a new OakBuffer object to be returned upon each next step. Scanning Big Data that way will create millions of ephemeral objects, possibly unnecessarily, since the application only accesses this object in a short and scoped time in the execution.
To avoid this issue, the user can use our new Stream Scan API, where the same OakBuffer object is reused to be redirected to different keys or values. This way only one element can be observed at a time. Stream view of the data is frequently used for flushing in-memory data to disk, copying, analytics search, etc.
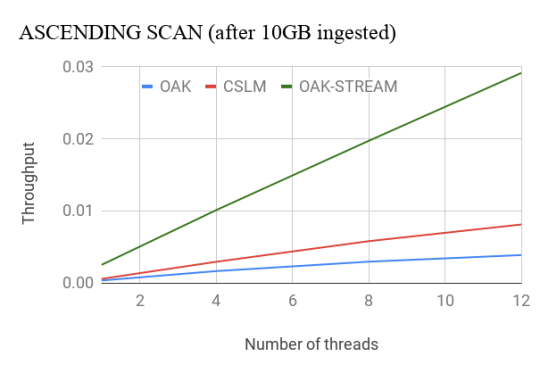
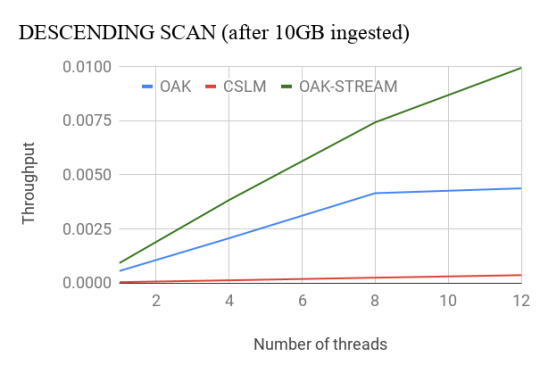
Oak’s Stream Scan API outperforms CSLM by nearly 4x for the ascending case. For the descending case, Oak outperforms CSLM by more than 8x even with less optimized non-stream API. With the Stream API, Oak’s throughput doubles. More details about the performance evaluation can be found here.
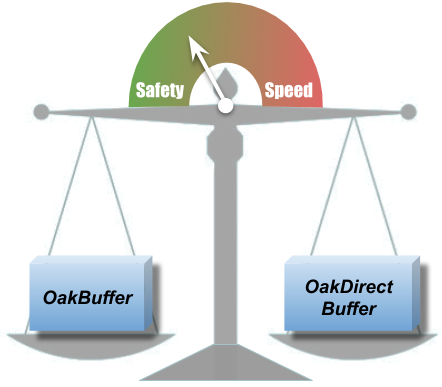
Safety or Performance? Both!
OakBuffers are core ZeroCopy API primitives. Previously, alongside with OakBuffers, OakMap exposed the underlying ByteBuffers directly to the user, for the performance. This could cause some data safety issues such as an erroneous reading of the wrong data, unintentional corrupting of the data, etc. We couldn’t choose between safety and performance, so strived to have both!
With Oak0.2, ByteBuffer is never exposed to the user. Users can choose to work either with OakBuffer which is safe or with OakUnsafeDirectBuffer which gives you faster access, but use it carefully. With OakUnsafeDirectBuffer, it is the user’s responsibility to synchronize and not to access deleted data, if the user is aware of those issues, OakUnsafeDirectBuffer is safe as well.
Our safe OakBuffer works with the same, great and known, OakMap performance, which wasn’t easy to achieve. However, if the user is interested in even superior speed of operations, any OakBuffer can be cast to OakUnsafeDirectBuffer.
Less (metadata) is more (data)
In the initial version of OakMap we had an object named handler that was a gateway to access any value. Handler was used for synchronization and memory management. Handler took about 256 bytes per each value and imposed dereferencing on each value access.
Handler is now replaced with an 8-bytes header located in the off-heap, next to the value. No dereferencing is needed. All information needed for synchronization and memory manager is kept there. In addition, to keep metadata even smaller, we eliminated the majority of the ephemeral object allocations that were used for internal calculations.
This means less memory is used for metadata and what was saved goes directly to keep more user data in the same memory budget. More than that, JVM GC has much less reasons to steal memory and CPU cycles, even when working with hundreds of GBs.
Fully Reusable Memory for Values
As explained above, 8-byte off-heap headers were introduced ahead of each value. The headers are used for memory reclamation and synchronization, and to hold lock data. As thread may hold the lock after a value is deleted, the header’s memory couldn’t be reused. Initially the header’s memory was abandoned, causing a memory leak.
The space allocated for value is exactly the value size, plus header size. Leaving the header not reclaimed, creates a memory “hole” where a new value of the same size can not fit in. As the values are usually of the same size, this was causing fragmentation. More memory was consumed leaving unused spaces behind.
We added a possibility to reuse the deleted headers for new values, by introducing a sophisticated memory management and locking mechanism. Therefore the new values can use the place of the old deleted value. With Oak0.2, the scenario of 50% puts and 50% deletes is running with a stable amount of memory and performs twice better than CSLM.
We look forward to growing the Oak community! We invite you to explore the project, use OakMap in your applications, raise issues, suggest improvements, and contribute code. If you have any questions, please feel free to send us a note. It would be great to hear from you!
In the previous update, we mentioned Improved Slow Node Tolerance, Multi-Threaded Rank Profile Compilation, Reduced Peak Memory at Startup, Feed Performance Improvements, and Increased Tensor Performance. This month, we’re excited to share the following updates:
Support for Approximate Nearest Neighbor Vector Search
Vespa now supports approximate nearest neighbor search which can be combined with filters and text search. By using a native implementation of the HNSW algorithm, Vespa provides state of the art performance on vector search: Typical single digit millisecond response time, searching hundreds of millions of documents per node, but also uniquely allows vector query operators to be combined efficiently with filters and text search - which is usually a requirement for real-world applications such as text search and recommendation. Vectors can be updated in real-time with a sustained write rate of a few thousand vectors per node per second. Read more in the documentation on nearest neighbor search.
Streaming Search Speedup
Streaming Search is a feature unique to Vespa. It is optimized for use cases like personal search and e-mail search - but is also useful in high-write applications querying a fraction of the total data set. With #13508, read throughput from storage increased up to 5x due to better parallelism.
Rank Features
The (Native)fieldMatch rank features are optimized to use less CPU query time, improving query latency for Text Matching and Ranking.
The new globalSequence rank feature is an inexpensive global ordering of documents in a system with stable system state. For a system where node indexes change, this is inaccurate. See globalSequence documentation for alternatives.
About Vespa: Largely developed by Yahoo engineers, Vespa is an open source big data processing and serving engine. It’s in use by many products, such as Yahoo News, Yahoo Sports, Yahoo Finance, and the Verizon Media Ad Platform. Thanks to feedback and contributions from the community, Vespa continues to grow.
We welcome your contributions and feedback (tweetoremail) about any of these new features or future improvements you’d like to request.
BySam Groth, Senior Software Engineer, Verizon Media
Do you have data in Apache Hadoop using Apache HDFS that is made available with Apache Hive? Do you spend too much time manually cleaning old data or maintaining multiple scripts? In this post, we will share why we created and open sourced the Data Disposal tool, as well as, how you can use it.
Data retention is the process of keeping useful data and deleting data that may no longer be proper to store. Why delete data? It could be too old, consume too much space, or be subject to legal retention requirements to purge data within a certain time period of acquisition.
Retention tools generally handle deleting data entities (such as files, partitions, etc.) based on: duration, granularity, or date format.
Duration: The length of time before the current date. For example, 1 week, 1 month, etc.
Granularity: The frequency that the entity is generated. Some entities like a dataset may generate new content every hour and store this in a directory partitioned by date.
Date Format: Data is generally partitioned by a date so the format of the date needs to be used in order to find all relevant entities.
Introducing Data Disposal
We found many of the existing tools we looked at lacked critical features we needed, such as configurable date format for parsing from the directory path or partition of the data and extensible code base for meeting the current, as well as, future requirements. Each tool was also built for retention with a specific system like Apache Hive or Apache HDFS instead of providing a generic tool. This inspired us to create Data Disposal.
The Data Disposal tool currently supports the two main use cases discussed below but the interface is extensible to any other data stores in your use case.
File retention on the Apache HDFS.
Partition retention on Apache Hive tables.
Disposal Process
The basic process for disposal is 3 steps:
Read the provided yaml config files.
Run Apache Hive Disposal for all Hive config entries.
Run Apache HDFS Disposal for all HDFS config entries.
The order of the disposals is significant in that if Apache HDFS disposal ran first, it would be possible for queries to Apache Hive to have missing data partitions.
Key Features
The interface and functionality is coded in Java using Apache HDFS Java API and Apache Hive HCatClient API.
Yaml config provides a clean interface to create and maintain your retention process.
Flexible date formatting using Java’s SimpleDateFormat when the date is stored in an Apache HDFS file path or in an Apache Hive partition key.
Flexible granularity using Java’s ChronoUnit.
Ability to schedule with your preferred scheduler.
The current use cases all use Screwdriver, which is an open source build platform designed for continuous delivery, but using other schedulers like cron, Apache Oozie, Apache Airflow, or a different scheduler would be fine.
Future Enhancements
We look forward to making the following enhancements:
Retention for other data stores based on your requirements.
Support for file retention when configuring Apache Hive retention on external tables.
Any other requirements you may have.
Contributions are welcome! The Data team located in Champaign, Illinois, is always excited to accept external contributions. Please file an issue to discuss your requirements.
In the April updates, we mentioned Improved Performance for Large Fan-out Applications, Improved Node Auto-fail Handling, CloudWatch Metric Import and CentOS 7 Dev Environment. This month, we’re excited to share the following updates:
Improved Slow Node Tolerance
To improve query scaling, applications can group content nodes to balance static and dynamic query cost. The largest Vespa applications use a few hundred nodes. This is a great feature to optimize cost vs performance in high-query applications. Since Vespa-7.225.71, the adaptive dispatch policy is made default. This balances load to the node groups based on latency rather than just round robin - a slower node will get less load and overall latency is lower.
Multi-Threaded Rank Profile Compilation
Queries are using a rank profile to score documents. Rank profiles can be huge, like machine learned models. The models are compiled and validated when deployed to Vespa. Since Vespa-7.225.71, the compilation is multi-threaded, cutting compile time to 10% for large models. This makes content node startup quicker, which is important for rolling upgrades.
Reduced Peak Memory at Startup
Attributes is a unique Vespa feature used for high feed performance for low-latency applications. It enables writing directly to memory for immediate serving. At restart, these structures are reloaded. Since Vespa-7.225.71, the largest attribute is loaded first, to minimize temporary memory usage. As memory is sized for peak usage, this cuts content node size requirements for applications with large variations in attribute size. Applications should keep memory at less than 80% of AWS EC2 instance size.
Feed Performance Improvements
At times, batches of documents are deleted. This subsequently triggers compaction. Since Vespa-7.227.2, compaction is blocked at high removal rates, reducing overall load. Compaction resumes once the remove rate is low again.
Increased Tensor Performance
Tensor is a field type used in advanced ranking expressions, with heavy CPU usage. Simple tensor joins are now optimized and more optimizations will follow in June.
…
About Vespa: Largely developed by Yahoo engineers, Vespa is an open source big data processing and serving engine. It’s in use by many products, such as Yahoo News, Yahoo Sports, Yahoo Finance, and the Verizon Media Ad Platform. Thanks to feedback and contributions from the community, Vespa continues to grow.
We welcome your contributions and feedback (tweetoremail) about any of these new features or future improvements you’d like to request.
In the previous update, we mentioned Ranking with LightGBM Models, Matrix Multiplication Performance, Benchmarking Guide, Query Builder and Hadoop Integration. This month, we’re excited to share the following updates:
Improved Performance for Large Fan-out Applications
Vespa container nodes execute queries by fanning out to a set of content nodes evaluating parts of the data in parallel. When fan-out or partial results from each node is large, this can cause bandwidth to run out. Vespa now provides an optimization which lets you control the tradeoff between the size of the partial results vs. the probability of getting a 100% global result. As this works out, tolerating a small probability of less than 100% correctness gives a large reduction in network usage. Read more.
Improved Node Auto-fail Handling
Whenever content nodes fail, data is auto-migrated to other nodes. This consumes resources on both sender and receiver nodes, competing with resources used for processing client operations. Starting with Vespa-7.197, we have improved operation and thread scheduling, which reduces the impact on client document API operation latencies when a node is under heavy migration load.
Adevelopment environment for Vespa on CentOS 7 is now available. This ensures that the turnaround time between code changes and running unit tests and system tests is short, and makes it easier to contribute to Vespa.
About Vespa: Largely developed by Yahoo engineers, Vespa is an open source big data processing and serving engine. It’s in use by many products, such as Yahoo News, Yahoo Sports, Yahoo Finance, and the Verizon Media Ad Platform. Thanks to feedback and contributions from the community, Vespa continues to grow.
We welcome your contributions and feedback (tweetoremail) about any of these new features or future improvements you’d like to request.
After being made aware of the COVID-19 Open Research Dataset Challenge (CORD-19), where AI experts have been asked to create text and data mining tools that can help the medical community, the Vespa team wanted to contribute.
Given our experience with big data at Yahoo (now Verizon Media) and creating Vespa (open source big data serving engine), we thought the best way to help was to index the dataset, which includes over 44,000 scholarly articles, and to make it available for searching via Vespa Cloud.
Please expect daily updates to the documentation and query features. Contributions are appreciated - please refer to our contributing guide and submit PRs. You can also download the application, index the data set, and improve the service. More info here on how to run Vespa.ai on your own computer.
In the January Vespa product update, we mentioned Tensor Operations, New Sizing Guides, Performance Improvements for Matched Elements in Map/Array-of-Struct, and Boolean Query Optimizations. This month, we’re excited to share the following updates:
Ranking with LightGBM Models
Vespa now supports LightGBM machine learning models in addition to ONNX, Tensorflow and XGBoost. LightGBM is a gradient boosting framework that trains fast, has a small memory footprint, and provides similar or improved accuracy to XGBoost. LightGBM also supports categorical features.
Matrix Multiplication Performance
Vespa now uses OpenBLAS for matrix multiplication, which improves performance in machine-learned models using matrix multiplication.
Benchmarking Guide
Teams use Vespa to implement applications with strict latency requirements and minimal cost. In January, we released a new sizing guide. This month, we’re adding a benchmarking guide that you can use to find the perfect spot between cost and performance.
Query Builder
Thanks to contributions from yehzu, Vespa now has a fluent library for composing queries - explore the client module for details.
Hadoop Integration
Vespa is integrated with Hadoop and easy to feed from a grid. The grid integration now also supports conditional writes, see #12081.
We welcome your contributions and feedback (tweetoremail) about any of these new features or future improvements you’d like to request.
About Vespa: Largely developed by Yahoo engineers, Vespa is an open source big data processing and serving engine. It’s in use by many products, such as Yahoo News, Yahoo Sports, Yahoo Finance, and the Verizon Media Ad Platform. Thanks to feedback and contributions from the community, Vespa continues to grow.
Privacy advocate Allie Funk was surprised to learn that her Delta flight out of Detroit airport would use facial recognition scans for boarding; Funk knew that these systems were supposed to be “opt in” but no one announced that you could choose not to use them while boarding, so Funk set out to learn how she could choose not to have her face ingested into a leaky, creepy, public-private biometric database.
It turns out that all of Funk’s suspicions were misplaced! It is as easy as pie to opt out of airport facial recognition: all you need to do to opt-out is:
* To independently learn that you are allowed to opt out;
* Leave the boarding queue and join a different queue at a distant information desk;
* Return to her gate and rejoin the boarding queue; and, finally
*NEW BLOGPOST* I am so tickled about the timing of our latest blogpost. I finally got around to finishing a recap of my #NEONdata workshop (it got pushed from peanut butter week ) and it happens that the same workshop is once more open for submissions! This time they’re going on the road so if folks at your institution are into amazing ecological data you’re in luck! Read more on the blog #linkinbio . . . #NEONscience #itsMeridith #ecology #dataaccess #rstats #rcode #dataavailability #workshop #recap #gradstudentlife #phdlife #exploreBoulder #BoulderCO #sciencelifestyle #STEMblog #STEMblogger (at Boulder, Colorado) https://www.instagram.com/p/BuM2yD5hynP/?utm_source=ig_tumblr_share&igshid=1pfomw6isrwhh
Make sure and read Meridith’s recap of her time at NEON! I think this is a really great post and resource for folks who are early on in their graduate careers and interested in working with big ecological data sets.
Paranoid pop for the age of information overindulgence. That sums up the ideal behind Big Data in one phrase. These are songs about love, connection, fear and belonging in a time where we experience e-love, e-connection, and in place of rejection we fear being “defriended”.
These are the ideas behind the lyrics of the debut EP by Big Data, appropriately titled “1.0″. Behind the emerald curtain…

































{kind=link}