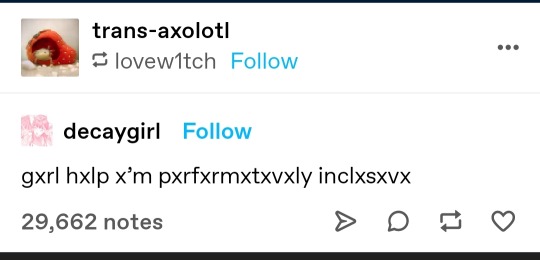The Vulcan salutation is such an iconic feature of the Star Trek universe that it has its own Wikipedia page and was added to the Unicode emoji set (). There are many ways to build a fictional reality, and gestures are one way of doing this.
These gestures are often Emblems, a type of gesture that has a fixed form and a fixed meaning for the group that use them. Gestures are distinct from performing magic or Jedi mind tricks, which in the fictional world are technically actions. There’s also this fun paper that looks at the way people in scifi use gestures to interact with computers and technology.
The intentional use and fixed meaning of emblem gestures mean that they can take on a life outside the fictional world. For example, here’s European Space AgencyastronautSamantha Cristoforetti in 2015 on the ISS, in a final salute to Leonard Nimoy.
Perhaps the most fascinating example of an emblem gesture extending beyond fiction in recent times has been the emergency of the three fingers salute from the Hunger Games books and films. This gesture has been used in pro-democracy protests in countries including Hong Kong, Thailand and Myanmar. The image below is from the 2021 protests in Myanmar.
These examples got me thinking about emblem gestures in other fantasy and scifi worlds. A recent one that came to mind was the two fingered blessing from Emperor Cleon in the television version of Foundation. Iconic enough in-world that statues of him are positioned using this gesture. It has a long history in Greek rhetoric and Christian iconography.
There’s a rude hand gesture in P.M. Freestone’s Shadowscent books - two fingers raised in a backhanded V, which parallels the Up Yours gesture in the UK and Australia, but also fits the in-world context as the offensive act is to plug someone’s nostrils (the hight of rudeness in a scent-focused world!).
I’m sure there are others too. I’ll undoubtedly start noticing them and add them to this post! (if you have any examples, I’d love to hear from you!)
I’m kind of glad to hear that everyone does this. Because it means it isn’t colonizer bullshit, it’s what everyone does. It’s just people discovering new things. Everyone goes:
“Oh hey these people have their own style of [language A’s word for thing. Say, what do you call it?”
“Oh it’s [language B’s word for thing].”
“Got it, it’s [language B’s word for thing] variety [language A’s word for thing]”
This is seriously not colonizer bullshit, it’s just one of the common ways that loan words work.
linguistics side of tumblr please talk about how this is a type of reduplication
Andso, a finger on the monkey’s paw curled.
This isn’t a type of reduplication. Reduplication is a very specific linguistic phenomenon which refers to the duplication of phonemes, morphemes, words, or whole ass clauses, as a way to changing meaning, add or remove emphasis, or a whole bunch of other things. But it’s specifically about the repeatition of sound: ‘bread’ is reduplicated to ‘bread bread’ or ‘brebread’ or ‘breadad’ or what have you depending on your reduplication scheme; and not ‘naan bread.’
Naan Bread and such are an example of an entirely different linguistic phenomenon centering reduncency, except it isn’t the sound that’s redundent but the meaning assigned to the sound. It’s the broadest terms, naan bread is a tautology(linguistics); narrowing in on specifics, it’s Semantic Pleonasm, in which two words which convey similar information are paired together to give the best combination of information; Think “tuna fish” for a monolingual example of variety-category semantic Pleonasm. Then getting to specifics, we have Bilingual Tautological/‘Pleonastic’ Expressions, in which the combination of words are sourced from two differet languages. This is where we find ‘Naan Bread’ and everything else this post is talking about.
I just have to say that. it would be amazing to me if every translation I read was extensively footnoted by the translator. I know this is not how everyone wants to experience a translation but I would like it and isn’t that what’s important
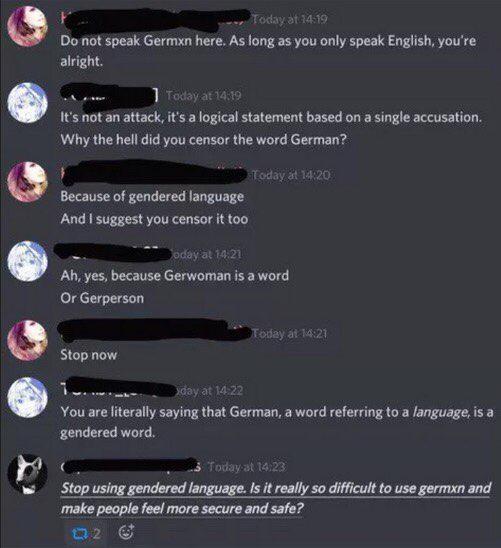
The implication that these people think “human” doesn’t include nonbinary people is telling.
Friendly reminder that the words man and woman are not related in English. As in, woman did not take the word man and add ‘wo’ to it.
Man started out as werman in old English, and woman started out as wīfman. The ‘man’ bit in both of these words means person. The ‘wer’ bit in werman gave us words like ‘werewolf’ - literally man-wolf. The ‘wīf’ part eventually became the word ‘wife’. Over time the word man lost the ‘wer’ bit and the word ‘wīfman’ eventually morphed into the word woman.
This is a linguistics speed run, but it’s why those terfy things with the word man crossed out are so ridiculous to me. Like where they go “woman” “human” etc. Because they love to ignore that the word man existing in any context is not a threat to them.
They even did this to cities like Manchester, England, claiming that the word ‘man’ in Manchester referred to men. It actually refers to breasts. The river Irwell in Manchester used to be known to the Celts as ‘Mamm’, meaning breast and probably relating to a river goddess. The Romans got there, asked the locals what they call it, and then added ‘castrum’, for fort. As the Romans built a fort down in modern day Castlefield. Mammcastrum became Manchester over time.
So yeah, I don’t even trust benign popular feminist ‘activism’ that goes around performatively removing the word man from things, because most often, it has nothing to do with the gender of man, and it just a word that happens to include those three letters. Yknow. Instead of helping vulnerable women, TERFs love to pretend they’re doing something smart by editing words with man in them.
Ramble over but that’s my ten cents
all very good info but can we go back to the part where Manchester means BREAST FORT???!
i want u guys to know that the university of sussex is constantly graffiti’d with among us crewmates and that the university keep desperately trying to clean it off but some hero with chalk keeps going back for more. the university sign has a permanent stain on the ‘sus’ of sussex
in case you don’t believe me here is photographic evidence
this is an entirely serious institution
The thing is
Essex = east sex
Sussex = south sex
Middlesex = still recognisable in modern English
Wessex = west sex, currently composed of Wiltshire/Somerset/Dorset etc
Someone explain the lack of north sex (Nosex)
(Okay okay okay I’m sorry about bringing actual pedantry onto what is an excellent joke post, but this did make me look up what the -sex names derived from and like… is there a Sex that all of these derive from? Although quite often placenames don’t evolve neatly like that. Anyway the answer is: kinda? Maybe?
The short answer is that -sex derives from -seaxe, or in other words, the Saxons. Essex was one of the kingdoms of the Anglo Saxon Heptarchy (7 kingdoms), along with Wessex, Sussex, Kent, Mercia, East Anglia, and Northumbria.
Yet, this still doesn’t really answer: east of *what*? West of *what*? South of *what*?
Unhelpfully: Mercia derives from a Latinisation of an Old English word, itself derived from Mercian, and essentially means “the border lands”, as it existed on a border with the Celtic Welsh to the west. Kent, meanwhile, seems to ultimately derive from an Old English word that likely means “land on the edge” (or “corner-land”, in reference to its shape and location on the isle of Britain). Northumbria, meanwhile, simply means “the land north of the Humber estruary”, which is quite a bit further south than what is now the boundary of the modern county of Northumberland.
But the most unhelpful thing of all is that none of the online sources I was able to consult today would commit to saying which of the 7 Anglo-Saxon kingdoms was established first (which might give a hint as to which was the “central” kingdom from which other designations might have derived). “Not much is known about the early years of the Anglo-Saxon settlement –” aaaugh, due to their not being a literate people (yet), and we can probably blame Bede for introducing folkloric distortions into the historical record.
At any rate, it’s entirely possible that “Essex” starts off as “the Saxon kingdom in the east” (or, insert the same concept here for Wessex or Sussex, if they were first), to differentiate it from the core area of Londinium. The Anglo-Saxon kingdoms arrive after the departure of Roman rule from the southern part of Britain, but of course nothing is ever as “neat” as one group departing and another group moving in (especially since the various Celtic British tribes were there all along). There were Angles and Saxons withing the “Roman” population who simply stayed, and a lot of modern archaeology is challenging the notion (from Bede) that in the power vacuum left by the Romans, the Angles and Saxons “invaded” Britain (it looks a lot more like it was a combination of some invasion but an awful lot of peaceful co-existence for a while).
Essex came to encompass the area of London, but by that point, Wessex and Sussex *might* have already derived their names either from their geographical relationship to Essex, or, to their own geographical relationship to the hub of London. Interesting (to, uh, me), but lacking a triumphant sense of “ah yes, that is definitely why!” Again: at least in what I was able to find out in some short online research, before pulling myself back up from the rabbit-hole.)
Many of us have heard that the word sophomore comes from the Greek sophosandmoros, meaning “wise” and “foolish” respectively. However, the person calling others “wise fools” should instead learn dramatic irony. Sophomore originates in the 1650′s as sophumer, which is indeed from the Greek sophos. A sophum was a learning exercise in which students would debate, making a sophumer an “arguer” rather than a “wise fool.”
This false etymology is probably very old, since our current spelling came about in the 1680′s (additionally making it a folk etymology), influenced by the Greek moros.
Current linguistics obsession: the difference in English between “few/little” and “a few/a little”
“He convinced few people” Negative connotation; he did not convince that many people.
“He convinced a few people” Neutral to positive connotation; he did manage to convince some people.
“They found a little food” “Neutral to positive connotation; it might not be a lot, but they did manage to find some food.
“They found little food” Negative connotation; that’s not going to be enough food.
I’m glad I was raised speaking English because I sure as hell would not want to try learning these different tricks as an adult second-language learner.
Here’s something a bit different! I decided to try my hand at my own little YouTube channel, somewhere at the intersection of linguistics and philosophy. This is my first video!
In a nutshell, there’s this kind of argument (really, a whole class of arguments) that you sometimes find in the discipline of theology: the Modal Ontological Argument. It’s “modal” because it uses a branch of logic called modal logic, which deals with concepts like possibility, impossibility, and necessity. It’s “ontological” because it talks about what can, cannot, and must exist (ontology is the philosophical study of being). But it uses a version of modal logic that doesn’t easily square with how humans actually use language. It’s a version of logic that’s useful to philosophers, because it lets you simplify larger, complex expressions into smaller, more readable ones. But it’s also pretty counterintuitive, and in the end it runs up against the discoveries that linguists have made about how we use words like “possible.” So, I made this video going into how that all works! ^_^
Thus July, the International Linguistics Olympiad (a problem-solving competition aimed at secondary school students) will be held in Dublin. Since I’ve been helping a bit to organize the French half of this year′s Canadian Linguistics Olympiad – which leads directly into the international event – I figured I’d share some of the relevant details here, in case you (or someone you know) might be interested in participating!
So, if you like riddles, love language, or just really need to get to Ireland, be sure to share this advert!
On Thursday, January 19th, there’ll be an info session at l’Université du Québec à Montréal (UQAM), with the competition itself happening at the end of this month. No previous training is needed, but a love of puzzles definitely helps!
The Language Conservancy does a lot of really interesting and amazing work for helping revitalize and raise awareness about Native American languages, and they’re worthy of your time and support, even outside the P4A. Check out their website, which has a ton of info about their activities.
If you don’t know about the Project for Awesome, it’s a yearly charity and awareness raising campaign on YouTube aimed at decreasing world suck. Find out more, and vote for videos, at the P4A site!
In the past few years, a number of films have made a point of Getting the Science Right. Interstellar (2014) famously consulted with astrophysicist Kip Thorne, in order to achieve a realistic on-screen depiction of black holes (amongst other things). Just last year, The Martian was praised for basing much of its appeal around its scientific realism.
Now, in 2016, the sci-fi film Arrival is attracting similar accolades for it’s portrayal of linguistics, and of how scientists approach solving a problem. One standout piece hails from Science vs. Cinema – a YouTube channel devoted to examining how Hollywood fares on various science-related matters:
Since the movie only had so much time to cover exactly how Amy Adams’ character Dr. Louise Banks unraveled the aliens’ writing system, let’s do a deep dive and actually answer the question:
How do linguists do what they do?
So, the short answer is pattern recognition. Just like how a physicist might toss a ball up into the air a bunch of times to figure out which rules it follows coming down (or toss some baryons at each other to see what comes out the other side), a linguist will observe how the sounds and symbols of a language regularly connect up to meaning. With even a small amount of data, a linguist can begin the process of uncovering the relationships that hold between speech and the world it’s used to represent.
What does this look like? Well, we don’t have any real alien languages to work with (for now), but we’ve got plenty of human languages to choose from – between six and seven thousand. So, let’s pick one, look at a few examples, and see what we find!
To get as far away from English as we can, let’s go to Kashaya – an endangered Pomoan language spoken in California. Unlike English, which is analytic and tends to keep its morpheme-to-word ratio low (relying heavily on word order to keep track of who’s doing what to whom), Kashaya is polysynthetic; it tends to pack lots of information into each word, by way of affixation, and has relatively free word order.
Now, about half the world’s languages don’t have any developed writing system associated with them; with those that do, many lack native representation, relying instead on some version of the Latin alphabet. Kashaya is one such language, with its written form having been developed by Dr. Robert Oswalt in the 1960s. In the examples that follow, you can think of each word as being written in a kind of quasi-IPA; the words on the left represent the actual sounds of the language, as understood and transcribed by a linguist, while the meanings hang in the right-hand column.
bahcúw
‘to jump’
bahcubedu
‘always jumps’
coqocedu
‘always shoots’
coqów
‘to shoot’
kelci
‘peek!’
kelcíw
'to peek’
coqo
‘shoot!’
(At this point, I should admit I grabbed this data from a linguistics assignment. In the context of the film, the Heptapod language doesn’t come with an instruction manual, so Louise has to employ a monolingual demonstration – a technique used to elicit linguistic data when no common tongue exists between the parties involved. If you want to see this in action [you do], I highly recommend having a look here. In under 40 minutes, and without any assistance, linguist Dan Everett works with a speaker of a language he has no knowledge of and manages to uncover basic facts about its word order, sound inventory, and morphology. It’s really an impressive thing to behold, even for other linguists.)
Let’s start by choosing two words which share some meaning, to see if we can figure out what else they have in common. Beginning with the words for ‘to jump’ and ‘always jumps,’ we might tentatively conclude that what they share – “bahc” – means ‘jump,’ and that “úw” and “ubedu” mark the verb as being tenseless andhabitual, respectively. But throwing a third word into the mix – “coqocedu” for ‘always shoots’ – forces us to either reject or revise our hypothesis; “ubedu” can’t mean ‘always,’ since the only common sounds between the second and third words are “edu.” What can we do?
Here, it helps to know a bit about what languages sometimes have up their sleeves. In this case, it’s important to notice that the first consonants – “b” and “c” – are repeated in “bahcubedu” and “coqocedu.” This looks like reduplication, which involves the repetition of some or all of a root word, sometimes with some modification. It’s not as exotic as it sounds, since English speakers use this strategy when treating something dismissively (e.g., “alien-shmalien”). So, Kashaya might instead express ‘always’ using partial reduplication, followed up with “edu.” We’d need more data to know for sure, but it’s a good start.
As for those shifting vowels – “bahcubedu” vs. “coqocedu”? Maybe they’re not part of the the affixes, after all; maybe they’re part of the verb! In fact, the fourth word – “coqów” – seems to confirm this, since they each tend to stick to one verb root pretty consistently. Which means we need to say something more about that tenseless marker: it’s really just a “w,” with some stress added onto the last syllable. And, again, it’s not so unusual for stress to play a role in grammar; “complex” can mean either “complicated” or “a bunch of buildings,” depending on where you put the main emphasis.
Looking at the rest of the list, we can add that the absence of an affix altogether apparently marks the verb as imperative, meaning it can be used to issue a command. So, all in all, just 7 words have told us something about the sounds used in Kashaya, whether or not it has stress and reduplication, how to mark verbs as tenseless, habitual, or imperative, and how to say “jump,” “shoot,” and “peek.” Not bad, eh?
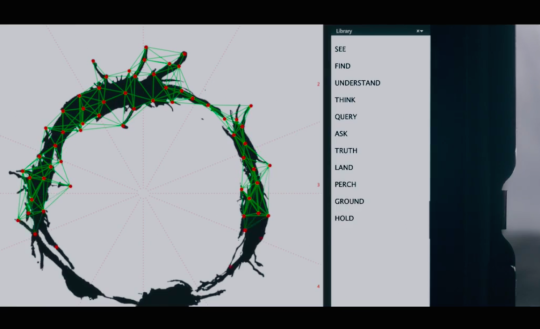
And this is just how Louise approaches Heptapod B, the film’s alien writing system. You can see for yourself, in this behind-the-scenes snapshot, that each logogram can be divided up into 12 segments. (Having an upper limit to sentences isn’t something you really see in human language, but of course this isn’t a human language!)
Looking closer, we can see the kinds of patterns we’d need to pay attention to, to begin cracking open the language. In the image below, the lowest righthand portion is shared across both logograms. (Actually, the bottom twelfth is the same across both of them, too. Maybe, like in Kashaya, this absence communicates something meaningful!)
And armed with this understanding, Louise devises a program to automatically analyze the logograms’ parts.
She even reverses the process by taking that database of segments and using it to construct her own logograms, in order to pose the all-important questions at the heart of the story.
Too cool!
It’s encouraging that the movie managed to capture the process so well (if only briefly), and it’s impressive that it’s resonated with audiences so much. I know I speak for more that just myself when I dare to hope this means we’ll be seeing more of a willingness on moviemakers’ parts to represent real science on the big screen. It might’ve sounded farfetched to say so just a few years ago, but a little linguistics in Hollywood seems not to be such an out-of-this-wolrd idea, after all!
If you enjoyed this story, and want to learn more about the linguists who worked on Arrival, definitely have a look at this!
And if you happen to be a student at the University of Pennsylvania, and you’re interested in helping to document and preserve endangered languages like Kashaya, be sure to check out the work being done by Professor Eugene Buckley, here! No experience needed!
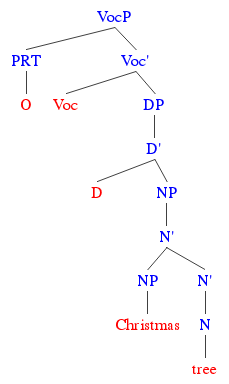
When the Ling Space team had the idea for some linguistics-themed Christmas apparel, the chance to syntax-ify the lyrics to ‘O Christmas Tree’ was just too good to pass up. Being the resident syntactician, I got to work on figuring out exactly what the structure for that opening line should look like. The “Christmas tree” part’s easy enough; that “O” turned out to be a very different story.
More below the fold!
Like we’ve talked about before, the theory that linguists developed back in the 1970s had it that every kind of phrase fit into the same basic shape — the X-bar schema. This meant that even simple nouns like “tree” would have a structure that looks like this:
That might seem like we’ve needlessly put a very small word into a very big house, but that extra room is crucial when determiners, adjectives, and prepositional phrases come over to visit:
With English being pretty easy-going when it comes to more than one noun living under the same roof, we’ve got our Christmas tree:
And with more recent developments in syntactic theory, like the DP Hypothesis discussed back in Episode 79, we have some good reasons to think that even bare noun phrases are actually cozily packaged up inside determiner phrases, like a present waiting to be unwrapped (think about how, in morphologically richer languages like French, even a simple phrase like “trees” needs an article before it, as in ”les arbres”):
But what about that “O”? What is it, even? Some version of “oh”? And where should it go?
At first, I just assumed it was an interjection (like “wow”) — one of the eight parts of speech that make up traditional grammar. Not that I’d thought about it much up until now, mind you. But, that seemed to be a reasonable guess. Problem is, the expression “oh” is typically associated with fear, surprise, or delight. In this case, it looks more like it’s pointing out the addressee, which is the person (or thing) being, well, addressed. After all, the accompanying lyrics mostly go on to describe the eponymous tree. That “O” looks to be doing the same job here that it’s doing in Canada’s national anthem ‘O Canada,’ or Walt Whitman’s poem ‘O Captain! My Captain!’
The good news is, linguists have a name for this! That “O” is a vocative particle. The bad news? That doesn’t mean much. The word “vocative” is there to point out that we’re dealing with vocative phrases, which are typically used to explicitly address the person being spoken to. In the lyric below, from the 1953 song ‘Santa Baby,’ that first bit functions as a vocative phrase, addressing the whole song to Santa Claus.
(1)Santa baby, slip a sable under the tree for me
English doesn’t oblige us to use “O,” but many languages regularly make use of such words. Catalan employs the particles “ei” and “eh.” Irish uses “a.” And, in fact, the “O” we’re currently interested in is just a carry-over from the original German ‘O Tannenbaum.’
But “particle”? That’s just what linguists call anything that they don’t know what it is. The infinitival marker “to” in English is sometimes called a particle, along with many other words in many other languages. By itself, it doesn’t tell us much. So what does the literature on this stuff have to say?
Unfortunately, as it turns out, there doesn’t really seem to be much research to speak of. And what little there is doesn’t seem to point to much of a consensus on the matter. So, how did we settle on the structure for our shirt? Well, to start, there seems to be a fundamental disagreement about the nature of vocative phrases: are they constituents?
Informally, a constituent is just a string of words that behave as a group. And on the surface, it might seem strange to question whether or not such phrases are bound together. But consider the following Italian data; while language generally allows any two like phrases to connect together with an “and” sandwiched between them, vocatives resist the trend.
(2a) O MariaePietro, Gianni è arrivato. o Maria and Pietro, Gianni is arrived
(2b) *O Mariaeo Pietro, Gianni è arrivato. o Maria and o Pietro, Gianni is arrived
Italian lets you double up on what’s inside the phrase (2a), but you can’t do the same for the whole thing over (2b). For some, this suggests that vocative particles aren’t really part of the noun phrases they’re coupled with, and instead form part of the structure of the overall clause. That way, only one ever rears its head, in the same way questions only ever have enough room for one set of question-y words at a time (3); “what will” and “when will” can’t coordinate with each other, since neither pair forms a constituent, with each word instead occupying a pre-determined position inside the sentence.
(3a)What will you be giving them Christmas Day?
(3b)When will you be giving them gifts?
(3c) *What willandwhen will you be giving them?
The general blueprint of sentences, then, would limit the number of particle-y vocatives to exactly one, at the very top, above everything else.
Still, others insist our dear “O” is closer to its noun phrase than to the clause that follows. And since it’s hard to make a shirt out of a non-constituent, we took the path of least resistance. That still leaves us with an open question, though: if vocative phrases are just bulked up noun phrases, why put the “O” up at the top, instead of putting it inside that empty Voc position a bit lower down? If anything’s going to form the core part of a vocative phrase, shouldn’t it be our particle?
Enter Latin. Many languages mark their vocatives with affixes instead of particles. William Shakespeare’s famous line “Et tu, Brute?” in the play ‘Julius Caesar’ has “Brutus” in his vocative form, with that “-e” replacing the nominative suffix “-us.” Other languages, like Romanian, can both directly mark their nouns (e.g., “grandpa”) as vocative, while also making use of a particle:
(4) bre tataie PRT grand’pa.VOC
The takeaway is that the information that a phrase is being used vocatively spreads our across two separate positions — one that can connect up directly to the noun, and one that shows up beside it. (French negation works similarly, as in “Ils n'aiment pas Noël.”) Any given language can make use of one of these positions (Latin), the other (archaic English), neither (Modern English), or both (Romanian).
In cases where the noun bears an affix, we suppose it’s moved up out of the NP/DP combo and into that Voc position, so that (4)’s structure looks something like this:
We can tell this is probably the right way to think about what’s going on, since names in Romanian (e.g., “Ion”) contain information related not only to their being marked as vocative, but to their being definite (i.e., as though they’ve picked up a hitchhiking article along their way up the tree):
(5) Ionelule Ionel.the.VOC
So, at last, we have our structure for “O Christmas tree.” Without any vocative affixes to speak of in English, the nouns stay put, and our lovely little particle “O” perches itself up on the highest branch. Mix in some atelierMUSE magic, et voilà!
I haven’t written anything for a while since I’ve been so busy recently (been working a lot on the typology of relative clauses - perhaps I’ll post something about that soon). This evening I watched an interview (on YouTube) from the late 1970’s (1977, I think) with Chomsky. The interview is from a series called “Men of Ideas” produced by the BBC.
It’s a great interview - stimulating and perceptive questions and, of course, stimulating and perceptive answers! Many things caught my attention, one of which being that Chomsky spoke of two factors playing a role in language design, namely the biological endowment (i.e. Universal Grammar (UG) - the species- and domain-specific cognitive ‘organ’ dealing with language) and linguistic experience (i.e. the primary linguistic data from which we acquire our native language(s)). The idea was that all humans are born with a capacity for language, i.e. UG is innate in humans, provided by our genetic makeup. The data we encounter as children is so scant and degenerate (full of false starts, sentence fragments, etc.) that it would be virtually impossible to acquire a grammar in the short amount of time that it takes any normal child to do so the world over…unless we came pre-programmed for such a task. The idea was that UG was this pre-programming. UG was thought to be richly specified with linguistic principles (all genetically encoded) that would help children in the task of language acquisition by severely constraining the possible hypotheses that any child would postulate when acquiring a grammar to generate the data the child was exposed to. That was then.
Nowadays, Chomsky speaks not of two factors, but of three factors of language design. UG and the primary linguistic data are the first and second factors respectively. The third factor is made up of general principles of data analysis and efficient computation. The idea is that children can bring these domain-general (i.e. not exclusively related to language) tools to language acquisition. The third factor allows the first factor, i.e. UG, to be made much smaller. In other words, UG is no longer thought to be as richly specified as it once was. In fact, the aim is to make UG as small as possible. This is desirable for a number of reasons, but a particularly pertinent reason concerns the evolution of language, i.e. the evolution of the capacity for language in humans. As an 'organ’ of the mind, UG is a biological entity, and as such it must have evolved (though not necessarily through direct selection, as Chomsky points out in the interview!). Given that chimpanzees do not have UG, UG must have evolved some time in the last 5-7 million years or so. It is therefore unlikely that something as rich and complex as UG as it was originally conceived could have evolved in such an evolutionarily short space of time. The third factors, however, need not be specific to language, nor do they need to be specific to humans. Therefore, it is conceptually desirable if we can explain the design of language in terms of third factors. This is, in fact, viewed as the only source of principled explanation in Chomskyan syntax nowadays.
Importantly, although UG is far smaller than it was and may only consist of very few things (a recursive structure building operation at the very least), it is nevertheless still thought to exist. The UG hypothesis in its modern incarnation is thus still very different from approaches which deny the existence of UG altogether.
Anyway, if you’re interested, I suggest reading Chomsky’s (2005) paper:
Chomsky, N. (2005). Three Factors in Language Design. Linguistic Inquiry 36: 1, 1-22.
Danny Fox presents the following examples showing how multiple ellipsis can result in a mix of strict and sloppy interpretations (Fox 2000: 117).
(19) a.
Smithers[1] thinks that his[1] job sucks. Homer does, too <think that Homer’s job sucks>. However, Homer’s wife doesn’t <think that Homer’s job sucks>.
(19) b.
Smithers[1] thinks that his[1] job sucks. Homer does, too <think that Homer’s job sucks>. However, Marge doesn’t <think that Homer’s job sucks>.
I always like it when examples from The Simpsons make it into academic linguistic work, but I especially like what Fox writes in his footnote:
“This [the evidence against the formal constraint Fox is taking issue with] can be seen in (19b), where the mixed reading is available for educated people (those who know that Marge is Homer’s wife).”
Reference: Fox, D. (2000). Economy and Semantic Interpretation. Cambridge, MA: MIT Press.