I actually think the real advantage tumblr has over other websites is the ability of “reblogging” to create posts with contributions from multiple users. This allows people to build on others’ posts, whether that’s derailing them with a terrible joke, drawing the scenario proposed as a comic, answering the question posed originally in lively essay format, or rewriting the previous interaction as a scene in Shakespearean iambic pentameter.
This is also why Tumblr is hard to make profitable. Individual users have relatively little power to create good content. It’s interactions between users that actually creates the good content, and therefore, no one involved in the good stuff on Tumblr can really claim to “own” it or be the “creator.”
Posts have to navigate through Tumblr to pick up the people that can add to them in a constructive way, and then when users interact, the whole interaction can spread across the website as a new evolution of the content. There’s no way to simplify this process.
Theres a whole ecosystem running here. It’s not as simple as Creators and Consumers, and you can’t simplify it to that. That’s not how ART works, let alone posts. There’s symbiosis. The users that do the nitrogen fixation aren’t the ones photosynthesizing. The detritivores can’t also be the predators. The “rappers doing normal shit blog” has a different niche than the person that asks why Lil Wayne has socks on in the jacuzzi, who has a different niche than the person who says “those are his hooves, you bitch!”
It’s like bioavailability, you see. The user that responds “Those are his hooves, you bitch” is like a predator on a high trophic level, unable to directly feed on producers, needing primary consumers to convert the post into a form that makes a punch line possible.
This is what I love about Tumblr. It feels more like discussing a common matter with the people you meet while out for a walk than trying to hold a conversation with twenty people at once in a crowded room
I have seen a lot of these “how Tumblr works”-posts going around lately, and I think this one says it really well. I’m not necessarily here for the original post but for the snowball effect of a reblog chain that hopefully follows
College dorms in the late 90s early 2000s had poster boards everywhere and everyone stuck random notes on, some that continued a conversation. Tumblr makes me think of college posterboards.
Tumblr is improv. We’re constantly yes-anding each other.
I knew a linguist once who did a study on conversations in bathroom graffiti and that’s something else tumblr conversations remind me of.
An interesting internet culture thing I’ve never seen discussed is the “shared unstated”, where someone will say an incomplete sentence leaving out the most crucial information and yet it conveys an idea or emotion that everyone just. Gets.
An example of this is when people are reacting emotionally to something and they just say “I’M” and then leave off any verbs or anything else in general. We started out with “IM SCREAMING” or “IM DYING” and then evolved just into “I’M” which holds almost no information and yet, we get it.
Another example is the recent “one of the most of all time” phrase. The first time I saw it was about a very strange looking little creature, like maybe one of those rodents with the elongated snout, and one of the comments was “one of the most animals of all time.” The crucial adjective is missing but the Vibe is present. Is it one of the most beautiful animals, the best animals, the coolest animals, the weirdest animals? Certainly not. And we all know it’s not. But it definitely is one of the most animals, which is a separate thing. Idk. It just is. We just get it. It’s the shared unstated.
An interesting question found its way into our inbox recently, asking about relative clauses in Swedish, and wondering whether their unique characteristics might pose a problem for some of the linguistic theories we’ve talked about on our channel. So if you want a discussion of syntax, Swedish, and subjacency (with some eye-tracking thrown in), this is for you!
So yes, there is a hypothesis that Swedish relative clauses break one of the basic principles by which language is thought to work. In particular, it’s been claimed that one of the governing principles of language isSubjacency, which basically says that when words move around in a sentence, like when a statement gets turned into a question, those words can’t move around without limit. Instead, they have to hop around in small skips and jumps to get to their destination. To make this more concrete, consider the sentence in (1).
(1) Where did Nick think Carol was from?
The idea goes that a sentence like this isn’t formed by moving the word “where” directly from the end to the beginning, as in (2). Instead, we suppose that it happens in steps, by moving it to the beginning of the embedded clause first, and then moving it all the way to the front of the sentence as a whole, shown in (3).
(2a) Did Nick think Carol was from where?
(2b) Where did Nick think Carol was from _?
(3a) Did Nick think Carol was from where?
(3b) Did Nick think where Carol was from _?
(3c) Where did Nick think _ Carol was from _?
One of the advantages of supposing that this is how questions are formed is that it’s easy to explain why some questions just don’t work. The question in (4) sounds pretty weird — so weird that it’s hard to know what it’s even supposed to mean. (The asterisk marks it as unacceptable.)
(4) *Where did Nick ask who was from _?
Theexplanation behind this is that the intermediate step that “where” normally would have made on its way to the front is rendered impossible because the “who” in the middle gets in its way. It’s sitting in exactly the spot inside the structure of the sentence that “where” would have used to make its pit stop.
More generally, Subjacency is used as an explanation for ‘islands,’ which are the parts of sentences where words like “where” and “when” often seem to get stranded. And one of the most robust kinds of island found across the world’s languages is the relative clause, which is why we can’t ever turn (5) into (6).
(5) Nick is friends with a hero who lives on another planet
(6) *Where is Nick friends with a hero who lives _?
Surprisingly, Swedish — alongside other mainland Scandinavian languages like Norwegian — seems to break this rule into pieces. The sentence in (7) doesn’t have a direct translation into English that sounds very natural.
(7a) Såna blommor såg jag en man som sålde på torget
(7b) Those kinds of flowers saw I a man that sold in square-the (gloss)
(7c) *Those kinds of flowers, I saw a man that sold in the square
So does that mean we have to toss all our progress out the window, and start from scratch? Well, let’s not be too hasty. For one, it’s worth noting that even the English version of the sentence can be ‘rescued’ using what’s called a resumptive pronoun, filling the gap left behind by the fronted noun phrase “those kinds of flowers.”
(8) Those kinds of flowers, I saw a man that sold them in the square
For many speakers, the sentence in (8) actually sounds pretty good, as long as the pronoun “them” is available to plug the leak, so to speak. At the very least, these kinds of sentences do find their way into conversational speech a whole lot. So, whether a supposedly inviolable rule gets broken or not isn’t as black-and-white as it might appear. What’s maybe a more compelling line of thinking is that what look like violations of these rules on the surface can turn out not to be, once we dig a little deeper. For instance, the sentence in (9), found in Quebec French, might seem surprising. It looks like there’s a missing piece after “exploser” (“blow up”), inside of a relative clause, that corresponds directly to “l'édifice” (“the building”) — so, right where a gap shouldn’t be possible.
(9a) V'là l'édifice qu'y a un gars qui a fait exploser _
(9b) *This is the building that there is a man who blew up
But that embedded clause has some very strange properties that have given linguists reasons to think it’s something more exotic. For one, the sentence in (9) above only functions with what’s known as a stage-level predicate — so, a verb that describes an action that takes place over a relatively short period of time, like an explosion. This is in contrast to an individual-level predicate, which can apply over someone’s whole lifetime. When we replace one kind of predicate with another, what comes out as garbage in English now sounds equally terrible in French.
(10a) *V’là l'édifice qu'y a un employé qui connaît _
(10b) *This is the building that there is an employee who knows
Interestingly, stage-level predicates seem to fundamentally change the underlying structures of these sentences, so that other apparently inviolable rules completely break down. For instance, with a stage-level predicate, we can now fit a proper name in there, which is something that English (and many other languages) simply forbid.
(11a) Y a Jean qui est venu
(11b) *There is John who came (cannot say out-of-the-blue to mean “John came”)
For this reason, along with some other unusual syntactic properties that come hand-in-hand, it’s supposed that these aren’t really relative clauses at all. And not being relative clauses, the “who” in (9) isn’t actually occupying a spot that any other words have to pass through on their way up the tree. That is, movement isn’t blocked like how it normally would be in a genuine relative clause.
Still, Swedish has famously resisted any good analysis. Some researchers have tried to explain the problem away by claiming that what look like relative clauses are actually small clauses — the “Carol a friend” part of the sentence below — since small clauses are happy to have words move out of them.
(12a) Nick considers Carol a friend
(12b) Who does Nick consider _ a friend?
But the structures that words can move out of in Swedish clearly have more in common with noun phrases containing relative clauses, than clauses in and of themselves. In (13), it just doesn’t make sense to think of the verb “träffat” (“meet”) as being followed by a clause, in the same way it did for “consider.”
(13a) Det har jag inte träffat någon som gjort
(13b) that have I not met someone that done
(13c) *That, I haven’t met anyone who has done
So what’s next? Here, it’s important not to miss the forest for the trees. Languages show amazing variation, but given all the ways it could have been, language as a whole also shows incredible uniformity. It’s truly remarkable that almost all the languages we’ve studied carefully so far, regardless of how distant they are from each other in time and space, show similar island effects. Even if Swedish turns out to be a true exception after all is said and done, there’s such an overwhelming tendency in the opposite direction, it begs for some kind of explanation. If our theory is wrong, it means we need to build an even better one, not that we need no theory at all.
And yet the situation isn’t so dire. A recent eye tracking study — the first of its kind to address this specific question — suggests a more nuanced set of facts. Generally, when experimental subjects read through sentences, looking for open spots where a dislocated word might have come from as they process what they’re seeing, they spend relatively less time fixated on the parts of sentences that are syntactic islands, vs. those that aren’t. In other words, by default, readers in these experiments tend to ignore the possibility of finding gaps inside syntactic islands, since our linguistic knowledge rules that out. And in this study, it was found that sentences like the ones in (7) and (13), which seem to show that Swedish can move words out from inside a relative clause, tend to fall somewhere between full-on syntactic islands and structures that typically allow for movement, in terms of where readers look, and for how long. This suggests that Swedish relative clauses are what you might call ‘weak islands,’ letting you move words out of them in some circumstances, but not in others. And this is in line with the fact that not all kinds of constituents (in this case, “why”) can be moved out of these relative clauses, as the unacceptability of the sentence in (14) shows. (In English, the sentence cannot be used to ask why people were late.)
(14a) *Varföri känner du många som blev sena till festeni?
(14b) Why know you many who were late to party-the
(14c) *Why do you know many people who were late to the party?
For reasons we don’t yet fully understand, relative clauses in Swedish don’t obviously pattern with relative clauses in English. At the same time, the variation between them isn’t so deep that we’re forced to throw out everything we know about how language works. The search for understanding is an ongoing process, and sometimes the challenges can seem impossible, but sooner or later we usually find a way to puzzle out the problem. And that can only ever serve to shed more light on what we already know!
What can silence tell us about the syntax of a sentence? How do we know what meaning to fill in when words are missing? In this week’s episode, we talk about ellipsis: what rules are at work to tell us how to use it, how sentence structure plays into what words we can leave out, and whether words are even missing at all, or just hiding.
We’re really glad to be back and sharing stuff with you all again! Looking forward to hearing what you have to say.
Going back and doing some cleaning as we get ready to do new things, I realized I never posted our extended discussion on event semantics here! So if you want some good discussion of how we can best capture exactly what verbs are doing semantically, continue on here.
Back in our episode about event semantics, we argued that we’ve actually been thinking about verbs all wrong in terms of how we treated them semantically. Up until now, we’ve treated verbs as though they were kind of like naturally occurring versions of the predicate symbols you find in the artificiallanguage of logic. So we could model the meaning of a verb like “travel” by taking advantage of this correspondence.
(1) “travel” ≈ Txy
Those variable symbols “x” and “y” following the predicate capture the fact that a verb like “travel” tends to combine with both travelers and destinations, in order to produce complete sentences. Borrowing letters nearer to the beginningof the alphabet to stand in for specific people and places, replicating those completed sentences in logic is fairly straightforward.
(2) “Athan traveled to London” ≈ Tal
After giving it some thought, though, we decided that a better way to think of the meaning of a verb like “travel,” along with other verbs, is not to treat it as a description of an individual, or even a relation between individuals and locations, but a property of events. Using this new logic, the meaning of “travel” would look more like “Te,” signifying that the act of traveling really refers to a set of coordinates in space and time — that is, an event. The verb “travel,” then, picks out any and all instances of traveling, in a way similar to how the noun “scientist” picks out, well, anyone who’s a scientist!
(3) “travel” ≈ Te
In our updated system, the meaning of “Athan traveled to London” now looks like a different kind of logical statement — one that’s existentially quantified. That means it’s a statement saying there’s at least one event out there in the world that fits the bracketed description following the backwards “E.”
In particular, it says there exists an instance of traveling, and that the person doing the traveling — the agent — is Athan, and that the destination is London. As you can see, the job of introducing other information, either about who did it, or how it happened, falls to other constituents. (We left it open exactly how the events described by verbs become existentially quantified, but a good first guess is that it’s tense that does the job, alongside locating the event in time.)
In making this move, we’ve ended up changing the typical verb’s argument structure, which is something we’ve touched on before. It means that we’ve fiddled with the number and kinds of things that any given verb is built to combine with. A verb like “hallucinate,” on a conceptual level, doesn’t combine directly with its subject anymore; instead, it’s meant to combine with an event, with the subject coming in obliquely. In the language of the lambda calculus, which is especially useful for keeping track of what combines with what, the meaning of “hallucinate” shifts over from (5a) to (5b) — from a function that accepts individuals as its input, to one that accepts events.
(5a) λ x . x hallucinated
(5b) λ e . e is an event involving hallucination
But it seems fair to ask whether this applies across the board: are all verbs created equal? Well, consider the following two sentences.
(6a) There’s a man drinking whiskey
(6b) *There’s a man liking whiskey
While the first sounds perfectly natural, the second seems off. And intuitively, the most noticeable difference we might point to between these verbs is that the first describes something done over a shorter period, while the second applies to an individual over a longer stretch, maybe even a lifetime. A bit more technically, linguists have attributed the split behaviours of these words to the fact that “drink” is a stage-level predicate, while “like” is an individual-level predicate.
Digging even deeper, it’s been recognized that more punctuated events (e.g., arriving, noticing, exploding) form only a small part of a much larger category of eventualities, which isn’t just some undifferentiated mass, but also includes things like lengthier processes(e.g., speaking, walking, sleeping) and even longer-term states(e.g., knowing, owning, loving).
The underlying difference, then, between stage-level verbs like “drink” and individual-level verbs like “like” might simply be that they apply to different kinds of eventualities (i.e., processes vs. states). It’s even been suggested that individual-level words dispense with event-based logic entirely, and work more like the predicates found in classical logic. This would actually go a long way in explaining why expressions of time and space, which we supposed place restrictions on events, don’t go well with every verb.
(7a) Katarina often speaks German
(7b) *Katarina often knows German
(8a) Ted is being held captive in the facility
(8b) *Ted resembles his father in the facility
It could also explain why perception verbs like “see” and “hear” and “smell,” which seem to be looking to combine with something fairly ‘eventive’ in nature, get along with some verbs much better than others.
(9a) Cassandra saw James talk to himself
(9b) *Cassandra saw James love her
So the innovation of event semantics not only gives us a way of explaining exactly how adverbs and prepositional phrases fold into sentences, as we spelled out in the episode — it can also account for the fact that verbs regularly contrast with each other regarding the sorts of sentences we find them in to begin with. And having only really scratched the surface, you can be sure we’ll have a lot more to say about this topic in episodes to come!
It’s not often that a horror movie manages to snag the top spot at the box office, and even rarer that it should reclaim first place in its third weekend, after having dropped down to number two. But that’s exactly what John Krasinki’s new film A Quiet Place pulled off, to the tune of a 50 million dollar opening, and over 200 million worldwide. What’s more remarkable, though, is that such a mainstream movie would commit so steadfastly to its premise — where any sound made can attract the attention of deadly monsters — and silently render almost every word of dialogue in American Sign Language (ASL). And as a result, actress Millicent Simmonds explains, the film winds up being especially significant for the deaf community.
Simmonds, who is deaf herself, actually spent time on set helping the other actors learn ASL, which generally goes underrepresented in mainstream cinema. And the importance of casting a deaf actor and using genuine sign language is something she’s been quick to underscore. “I think it’s important in the deaf community to advocate for and be a representative for this story,” she says, “a story that might inspire directors and other screenwriters to include more deaf talent and be more creative in the way you use deaf talent.” “What I hope is that I can show [my community] you can do anything,“ she goes on to explain, “not only become an actor, but a writer, a teacher, a pilot, anything you want to do is possible.”
And for those who’ve now seen the film, there’s yet another linguisticky easter egg to be found, around which the whole final act of the movie turns. So if you don’t want to be spoiled, be sure to stop reading right now, because principle plot points abound below the fold! ^_^
A cool discussion of A Quiet Place from our staff writer Stephan! There’s some good explanation under the fold, too, but it is spoiler-y. Still, I learned a bunch!
The comparative sentences that we talked about in our episode on grammatical illusions, like in (1) below, are surprising because of how far away people’s first impressions tend to sit from reality.
(1) More people have been to Montreal than you have.
When you give it a moment’s thought, it becomes clear there’s a sizeable gap between how sensible it seems at first glance, and how little information it actually communicates.
Even the illusory sentence in (2a) below, which was rated in experiments as being nearly as acceptable as the perfectly ordinary sentence in (2b), still falls apart when you try to put its pieces together. Spelled out, its meaning ends up as something like “how many girls ate pizza is greater than how many we ate pizza,” which doesn’t quite work; pronouns, even plural ones like “we,” can’t easily be combined with counting expressions like “how many.”
(2a) More girls ate pizza than we did
(2b) More girls ate pizza than boys did
But we still manage to interpret these sentences, in a way that fits the machinery made available by our mental grammar. As we discussed in the episode, the fact that we’re also able to count how many times something happened, in addition to how many there are of something, gives us a kind of half-working backdoor into understanding them. But, there’s another kind of illusion that’s even more striking, where there really isn’t any way at all to make sense of it. Try reading the following sentence aloud.
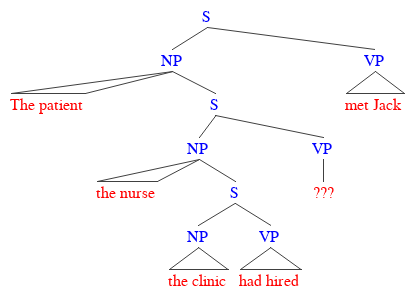
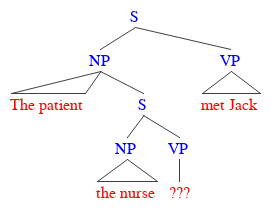
(3) The patient the nurse the clinic had hired met Jack
It seems pretty run-of-the-mill, pretty boring … except when you try to work out who’s doing what to who! It’s clear enough that the patient met Jack, and that the clinic’s doing some hiring, but what’s that nurse doing in the sentence? What’s his or her relationship with the patient? Or Jack? The nurse is just kind of … floating there, not really doing anything at all!
To make what’s going wrong more obvious, have a look at the simplified structure below. Each clause, whether it’s the overall sentence or an embedded one, has to have one subject noun phrase and one predicate verb phrase. Three clauses means three of each, but plainly, one of the verbs is simply missing in action!
This problem becomes unavoidable when we trim our tree and take out that lowest clause, giving us “The patient the nurse met Jack,” which really can’t mean much of anything. In fact, it’s a violation of a basic condition on the shape that sentences can take, known as the Theta Criterion, which essentially demands that verbs and their subjects have to match up one-to-one.
Sentences like the one in (3), then, end up forming a class of grammatical illusions that result from the so-called missing-VP effect. And as remarkable as they might seem already, things get even stranger when we consider their supposedly grammatical counterparts. Take the modified version below, with the missing VP put back in its place.
(6) The patient the nurse the clinic had hired admitted met Jack
While everything’s where it should be, the sentence has now become just about impossible to follow — or, at least, a lot harder to understand on a first pass than the simplified version in (7), where the lowest clause has once again been pruned from the tree.
(7) The patient the nurse admitted met Jack
This difficulty with understanding an otherwise perfectly grammatical sentence — at least, according to the rules we know about — is thanks to a phenomenon that’s been pondered over since at least the 1960s: centre embedding. While placing one clause right in the middle of another works fine once, as in (7), applying the same rule a second time over produces an incomprehensible mess, like in (6) above or (8) below.
(8) The dog that the cat that the man bought scratched ran away
Even though we can diagram these sentences out and force ourselves to follow the plot from one branch to the next with a whole lot of effort, they don’t really sit well when we hear them out loud. And this seems to suggest an upper limit on how many times our rules can apply. Except, we can find cases where this upper limit goes right out the window, like this 3-clause deep sentence!
(9) The reporter who everyone (that) I met trusts said the president won’t resign yet
With a quantifying expression and a pronoun in place of two more definite noun phrases, everything seems to be back in working order. And even more complex sentences than this can be found in writing, though they’re fairly rare.
So, what’s going on here? And how can we account for all this seemingly contradictory data? To start, it’s worth considering one of the most cited papers in all of psychology, The Magical Number Seven, Plus or Minus Two by George A. Miller. This work became famous not for putting an upper limit on how many times some rule or other could apply, but on how much information we’re able to hold in working memory. Like the title says, there seems to be a fairly low ceiling on how many ‘bits’ or ‘chunks’ we can actively hold in our heads at any given time. And this applies to processing language as much as anything else.
In fact, in a pair of papers co-written with linguist Noam Chomsky the following decade, Miller hypothesized that our trouble with centre embedding has more to do with limitations on our memory than on our grammar — which could account for why fiddling with the details (e.g. swapping certain kinds of nouns for others) can sometimes get around the problem.
But then, what exactly is going wrong in the sentence in (6), and more importantly, why should something meaningless like (3) get a free pass? Well, research into how we handle these sentences is very much active, but at least one recent theory takes some steps towards shedding a little light on the contrast.
As we encounter each new noun phrase in a sentence like (3), an expectation is set up that we’ll reach the end of that clause; in other words, we anticipate that we’ll encounter a matching verb phrase for each one. But something starts going wrong when we get to the lowest, most deeply embedded part of the sentence (i.e., “the clinic”).
When we hear that first verb phrase “had hired,” it slots into the lowest open position pretty easily, because that lowest and most recently encountered clause is the current focus of our attention. But when we encounter that second verb phrase, “met Jack,” we’re left at a disadvantage: we’ve got two more open positions to fill, but each one completes a clause that’s been interrupted by another one, having had the focus of attention wrenched away from it. What’s worse, all the clauses are syntactically identical, with nothing to differentiate between them. And, so, the little working memory we have is overloaded. We default to connecting that second verb phrase to the first, highest clause, and mistakenly assume we’ve finished building the sentence.
This Interference Account supposes that the two remaining incomplete clauses that were interrupted by an intervening relative clause compete and interfere with each other, overwhelming our limited memory and forcing us into making the wrong choice. It also explains why we have so much difficulty with centre embedding more generally: since we default to connecting that second verb phrase up to the highest clause, believing we’ve completed the sentence as a whole, encountering a third verb phrase in a sentence like (6) or (8) completely violates our expectations, and throws us for a loop.
So, the existence of acceptable nonsense like (3) and of well-formed but incomprehensible sentences like (6) doesn’t mean that our grammar is broken beyond repair; it just means that the rules that make up language are owned and operated by less-than-perfect users!
In our episode on the linguistics of propaganda, we talked a lot about how false implicatures can bend the truth just enough to sneak misconceptions into people’s heads, without them even necessarily realizing it. These are sentences where we imply something that isn’t true, without coming out and saying it overtly. But while we’ve touched on the topic of indirect speech before, we haven’t spent much time talking about why we do it. That is, why don’t we always just say what we mean, instead of risking a garbled message?
To get at an answer, let’s consider a few different uses we’ve got for indirect speech, and then see if we can figure out what they’ve got in common. Imagine, first, that you were out on a date, and as the evening winds down, you want things to move in a more romantic direction. Would you come right out and say it? Well, some of us might. But chances are that many would take a much more gentle approach — say, by asking if the other party wanted to come over to their place for coffee, or maybe to Netflix and chill.
Or let’s say you were driving a bit too fast, got pulled over, and were pretty sure you were about to get a ticket for a few hundred dollars that you really can’t afford. But let’s say you happened to have $50 on hand, and you’re feeling just brave enough to give a bit of bribery a go (NB: The Ling Space does not condone bribery). Would you move right to “I’ll give you money if you let me go”? Probably not, if you have any intention of staying out of jail. You’d likely try to be at least a little sly about it — maybe wondering aloud if the problem can’t be “taken care of here.”
Or picture the old cliché of a mobster extorting protection money from some local business, under penalty of violence. Since explicit threats are often illegal, but the enforcer still needs to get their message across, euphemistic speech ends up a vital part of their criminal enterprise. Phrases like “It’d be a shame if something happened to this fine establishment” replace outright intimidation, though the message remains the same.
In each of these cases, the speaker is affording themselves plausible deniability. Trying to move a new relationship (or even an old one) in a different direction can be potentially awkward, especially if the other party isn’t as interested as you. But if you play your cards close enough to the chest, and things go awry, you can always deny you were talking about anything more than coffee, or a night spent binge-watching the latest season of House of Cards.
And since bribing an officer is against the law, but might get you out of paying a hefty fine if they happen not to be the most honest cop in the land, the indirect approach lets you test the waters without committing yourself one way or the other. If they catch your drift, everybody leaves happy; if they don’t, well, you can hardly be found guilty for someone else misunderstanding your otherwise unimpeachable character! (More generally, shifting from one relationship type to another, like from one rooted in dominance to one that’s more transactional, can lead to tension, which is why bribing the maitre d’ for a better table can seem just as nerve-wracking, even if it’s not a crime.)
As for that threat: it might be hard getting something so weaselly to stick in court. On the face of it, after all, it really would be a shame if something happened! And they can always claim they were just expressing genuine concern, as laughable as that might seem.
And, so, indirect speech — and by extension plausible deniability — has many uses, both amongst those in positions of power, and those with none. Though paradoxical on the face of it, it can provide avenues for authoritarians to obtain and maintain control,* while protecting the powerless when all other exits are blocked.**
It’s fair to ask, though, why bribes and threats and the like that are so thinly veiled should work at all. Doesn’t everybody know what ‘Netflix and chill’ means by now? And is the mob really fooling anyone with their supposed concern for the well-being of the community? The secret lies in a concept we’ve spent some timepicking apartalready:mutual knowledge, otherwise known as common ground.
Mutual knowledge refers to the knowledge that exists between two or more speakers — not simply what both of them know, but what each of them knows the other one knows (and what each of them knows the other one knows the other knows, and so on). So while the intent of asking a partner over for coffee might seem obvious to both parties involved, because the invitation was indirect, there’s enough mutual doubt should either one decide to back out. If the answer is “no thanks,” embarrassment is saved, and everyone can go along pretending nothing ever happened. The possibility that either speaker doesn’t understand what just took place is small, but when we start asking whether each of them knows whether the other knows what happened, or knows that they know that they know, uncertainties multiply unbounded.
What indirect speech really does, then, is keep things off the record. While the information implicated by someone might be clear as day to anyone within earshot, that information manages not to work its way into the common ground. And, so, unlike base assertions, which fall square into the vessel of mutual knowledge we carry between us in any given conversation, implicatures float around just out of our reach — visible to everyone, but ephemeral enough for us to pretend they don’t even exist, if and when we need to.
Inour most recent episode, we talked about modals: words like “can”, “may”, “must”, and more. In particular, we took a deep dive into the semanticsof modal verbs. But we didn’t talk much about how they fit into the structures of sentences, and this seems to leave open some important questions. For starters, we made the claim that — in terms of their meanings — modal verbs combine with whole sentences, and not just the verb phrase that follows them. After all, the meaning of the sentence in (1a) seems to correspond to (1b).
(1a) The Observers must report to their commander.
(1b) It must be that the Observers report to their commander.
On the face of it, it seems weird that subjects in modal sentences appear separate from the main verb phrase, as in (1a), while being interpreted as though they were right next to them, as in (1b). It looks like this could be a big problem for our overall theory.
Thankfully, when we take into account some of the important discoveries we’ve talked about in past episodes, like the VP-Internal Subject Hypothesis, this problem goes away pretty quick. If it’s true that, in general, subjects start off somewhere insidethe verb phrase, and only latermove to a spot that’s higher up (and more to the left, at least in English), we can suppose that the meanings of sentences — modal and all — are simply computed beforethe subject starts moving around, instead of after.
But, this still leaves us wondering what part of the tree modal verbs typically call home. If you want to know more about how to set that up, keep reading!
The liminal zone between syntax and semantics (especially when we’re drawing mid-twentieth century trees) makes me completely bonkers. I don’t see the point of doing this kind of structural, ideologically-coded work when what’s at issue are conceptual relationships.
I mean, I guess I understand that it would be nice to represent relationships of meaning systematically and in terms of order, but I feel like the various models still don’t account for (any maybe shouldn’t) all the nuance of which human language is capable.
I’m always so much more comfortable using syntax to approach grammars and glosses rather than as a generative and constitutive system of language.
Please correct me if I’m wrong. I would love to hear some arguments for the coordination of semantics and syntax in this way. Or an explanation of how theoretical syntax improves our (english-speaking) understanding of semantics. OK, go!
So this is actually a really deep and interesting question that gets to the heart of linguistic theorizing, and even science in general. We’re going to try to do this without going through all the examples from the episode and the original post, but I hope it still makes sense!
Let’s start with what we said in our post about the apparent tension between modal verbs combining with whole sentences on a conceptual level, while being sandwiched in between subjects and verb phrases on a syntactic one. We could, in principle, rework the meaning we’ve assigned to modal verbs to make them work without the added complication of subjects moving around inside sentences. That is, we could paint a superficially simpler picture of how the meanings of these sentences come about. But removing the complexity from one part of a theory often ends up hiding it in some other part of that same theory. And so, even though we could tweak our definition of modal verbs to work in a syntactically simpler system (i.e., one that very literally has fewer moving parts), that new definition is made more complex. To get a bit technical, it goes from a simple characteristic function to a somewhat fancier function-valued function, which is a kind of higher-order function (representing a kind of logic that’s a step above the ordinary).
It turns out we can’t have both a simple syntactic representation, and a simple semantic one, because the order that one thing happens in influences the order that another thing happens in, and ignoring this would be like trying to put your pants on after putting on your shoes. So, the theory as a whole becomes simpler in one way, but more complicated in another. It’s this kind of unavoidable choice that has to be made, where to put the complexity, and we made it the way we made it because we already have other reasons to think it’s actually the syntax that’s complicated in this case, and not the semantics.
On supposing that there are actually two different spots in any given syntactic tree where modal verbs might live, depending on their flavour: this is actually practically useful. We guessed that knowledge-based modal verbs are relatively high up in the structure of any given sentence, while rule-based modal verbs are much lower down. To put it another way, we supposed that some modal verbs are structurally closer to the subject, with lots of room down below, while others are structurally closer to the verb phrase, making things more cramped. And this actually ends up having observable consequences, since in the case of higher, knowledge-flavoured modal verbs, there’s room enough between them and the verb phrase for all kinds of auxiliary verbs, like in “Peter must have been telling the truth.” But with lower modal verbs, that are about rules instead of knowledge, and which don’t leave as much space between themselves and the verb phrase, we don’t end up seeing all these intervening auxiliary verbs, as in “Peter must tell the truth.” So it looks like there’s some reality to there being a couple of different places for modal verbs to hang out, which has a real effect on the kinds of sentences we can build. And it’s worth mentioning at this point that we do find sentences with two modal expressions in them, and that when we do, the knowledge-y modal always seems to come before the more rule-ish one, like in “Peter must have to tell the truth.” We might be able to explain all these facts using simpler structures, but chances are that the meanings that come out of it get pretty sophisticated pretty quickly.
Finally, let’s look at what we said about the internal syntax of modal phrases. On one level, it’s just useful to represent things this way, to be able to visualize all the pieces and parts that go into building the meanings of these sorts of sentences. But in principle, we could simplify both the definitions of modal verbs and their surrounding structures, without any obvious trade-offs. And some linguists actually go ahead and do this. However, there are reasons to think that (for example) the modal base is on some level really present inside the trees we build in our heads. For one, sometimes the modal base is actually pronounced, as the topic of the sentence: “In view of the rules, Peter must tell the truth.” But even when it’s left out, because the context makes it obvious what’s being talked about, there are still reasons to suppose that, at a minimum, there’s something there in the tree that corresponds to it. In particular, when we get to talking about conditional (if-then) sentences like “If he wants to stay out of trouble, Peter must tell the truth,” it’s useful to think of that “if” part of the sentence as restricting, or limiting, the modal base. And that’s much easier to do if the modal base is, although unpronounced, somehow actually there in the tree. It could probably be done other ways, but that likely means supposing there are a couple different kinds of modal verbs – some that fit comfortably into conditional sentences, and some that don’t – and I’m not sure there’s any good reason to think that we have twice as many modal verbs in our vocabulary as we think we do!
And we definitely take the point that, as we’ve presented things, we don’t even come close to fully capturing all the variety and nuance found in human language. Unfortunately, there just isn’t enough space to cover everything in one go. But we’ll for sure be back to talk more about modal verbs in the future, and what we find when we look at other languages. It’s a gigantic and fascinating topic, with many different dimensions to it! And with the basics out of the way, we can now start to get to the good stuff! ^_^
Inour most recent episode, we talked about modals: words like “can”, “may”, “must”, and more. In particular, we took a deep dive into the semanticsof modal verbs. But we didn’t talk much about how they fit into the structures of sentences, and this seems to leave open some important questions. For starters, we made the claim that — in terms of their meanings — modal verbs combine with whole sentences, and not just the verb phrase that follows them. After all, the meaning of the sentence in (1a) seems to correspond to (1b).
(1a) The Observers must report to their commander.
(1b) It must be that the Observers report to their commander.
On the face of it, it seems weird that subjects in modal sentences appear separate from the main verb phrase, as in (1a), while being interpreted as though they were right next to them, as in (1b). It looks like this could be a big problem for our overall theory.
Thankfully, when we take into account some of the important discoveries we’ve talked about in past episodes, like the VP-Internal Subject Hypothesis, this problem goes away pretty quick. If it’s true that, in general, subjects start off somewhere insidethe verb phrase, and only latermove to a spot that’s higher up (and more to the left, at least in English), we can suppose that the meanings of sentences — modal and all — are simply computed beforethe subject starts moving around, instead of after.
But, this still leaves us wondering what part of the tree modal verbs typically call home. If you want to know more about how to set that up, keep reading!
In our old system, we might’ve been happy dumping all our modal verbs into the bucket labelled “inflection.” And this seems reasonable at first, since like other kinds of inflection (e.g., tense, aspect, voice), modality sometimes appears as an affix on the verb.
(2) Turkish: gel-me-meli-siniz
come-ɴᴇɢ-ᴏʙʟɪɢ-2ᴘʟ
‘You ought not to come.’
But this probably isn’t the most sophisticated picture of how sentences get put together, given that concepts like tenseandmodalityare pretty different from each other. Moreover, if they really were members of the exact same category, you might not expect to find them showing up in the same place at the same time, like how a coin can’t land both heads and tails; in fact, most modal verbs have both present tense (may, can, shall, will) and past tense (might, could, should, would) forms.
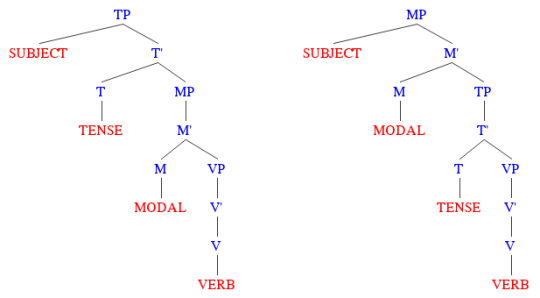
So, it probably makes more sense to think of modal verbs as appearing either somewhere just below, or somewhere just above, a dedicated tense phrase (TP).
It might even be both, given that modal verbs seem to interact with tense in subtly different ways, depending on their flavour:
(3a) Olivia could have used her powers, but she didn’t want to.
(3b) Olivia could have used her powers, but I haven’t found out yet.
After all, the sentence in (3a), which is saying something about Olivia’s abilities, seems to be about what was possible in the past(i.e., circumstances might be different now), whereas the sentence in (3b) says something about the speaker’s presentstate of knowledge. In other words, it looks as if the same modal verb either falls under the influence of the past tense, or else manages to escape it, depending on how it’s interpreted. This suggests there might be modal phrases both below and above the tense phrase.
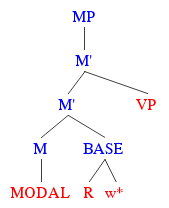
Lastly, it’s important to say something about how modal phrases actually get their meanings, and what that says about their internal structure. In the episode, we gave the modal verb “must” a meaning that looked like this:
(4) “must” = λ B . λ p . B ⊆ p
Reading it from left to right, it says that a modal verb first combines with some contextually defined modal base B — whose job it is to give the flavour, like whether it’s about belief or ability — and then goes on to combine with the sentence p, saying of the two that the set of worlds described by the base is a subset of the set of worlds described by the sentence. The modal base, then, is kind of like a pronoun; it’s like “they” or “them,” since it picks up its meaning from the context of the conversation. Whether “must” says something about someone’s knowledge, or about some set of rules to be followed, depends on the content of B. And if all this is right, it means that the structures of modal phrases — at a minimum — look something like this:
In reality, a bit more needs to be said about this, since a modal base by itself (as we’ve been thinking of it) can’t completely determine the meaning of the sentence. That’s because all the context can really provide is a general description of what’s being talked about — like whether what’s being discussed includes beliefs, rules, goals, abilities, et cetera. But, it can’t take the extra step of supplyingthose beliefs or rules or goals. To get a sense of why this makes a difference, take a look at the following sentence.
(5) I must report to the Colonel.
Imagine that this sentence is said by someone who mistakenly believes that the Colonel asked to see them. In this case, unbeknownst to the speaker, the sentence is false. And the reasonit’s false is because of what the actual requirements are, and not simply what the speaker might suppose they are. So, whether or not this kind of sentence ends up true or false depends on the way the world actually is, and not the way the speaker thinksit is. In other words, speakers can be uninformed about the content of the modal base, in a way that can’t be handled by context alone; that is, they can be mistaken about what the relevant rules or beliefs really consist of. And all of this means that the modal base must really be more like a function that’s meant to take some world as its input (the world in which the sentence is spoken), and then produce a set of worlds out of that, for the modal verb to work with — one that accurately captures whatever’s being talked about.
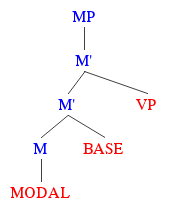
So, a more complete picture of what the internal structure of a modal phrase looks like is this:
What we see here is a function (sometimes called an accessibility relation) combining with a special kind of world pronoun. This relation R is what’s actually provided by the context of the conversation; it’s what determines the overall flavour. That w* symbol is what does the job of filling in the content of whatever’s being talked about, by providing the full set of rules or abilities under discussion. And it’s together that they determine the modal base — the set of worlds that modals like “must” or “may” go on to compare with the set of worlds described by the rest of the sentence. This way, we fully account for the fact that the truth of modal sentences depends not just on the context of the conversation, but on the way the world is.
As a final point, it’s worth mentioning that no matter which kind of structure we choose to represent modal sentences, none of them ever quite match up with how the sentence is actually pronounced. That is, the Logical Form of the sentence (how it’s interpreted), at least in these cases, is reliably different from its Phonetic Form (how it’s said). In fact, as it’s turned out, the idea that there are mismatches between how sentences are spoken and what they mean has played a big role in modern syntactic theory — one we’ll continue to talk about in the future!
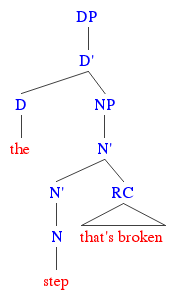
Inour episode on relative clauses, we focused on restrictive relative clauses, which we argued behave a lot like adjectives — specifically, intersective adjectives like “broken” and “curly.” In other words, if we think of both relative clauses and the nouns they combine with as sets, then the meanings we get out of connecting them together are whatever those sets share in common, or their intersection.
(1) “the broken step” ≈ “the step that’s broken”
And it makes sense to suppose that these kinds of relative clauses typically sit inside noun phrases, somewhere that’s neither too far up nor too far down the tree. After all, we can freely separate a relative clause from its host noun with a prepositional phrase, as in “the step in the middle of the staircase that’s broken,” suggesting the relative clause isn’t all that close to it to begin with. At the same time, the definite article seems to have a significant influence over everything that follows it, since out of all the steps and all the things that are broken, “the” picks out the one thing that’s both; this suggests that the relative clause is somewhere below the determiner.
But this isn’t the only kind of relative clause we find. If you want some more kinds of relative clauses, check below:
Consider the following sentence:
(2) Luke’s dad, who used to be a cheerleader, is also quite the prankster.
It doesn’t look like the relative clause “who used to be a cheerleader” is really restricting the meaning of “Luke’s dad.” In fact, if anything, it seems to be adding to it! In this case, we have what’s called a non-restrictive relative clause, which is often fenced off from the rest of the sentence with a slight pause (represented with commas).* And while restrictive relative clauses are generally thought of as combining meaningfully with the words around them, many linguists view non-restrictive relative clauses as being semantically separate from the rest of the sentence, as a kind of afterthought. The meaning of the sentence above, then, could be paraphrased like this:
(3) Luke’s dad is quite the prankster. Note that he used to be a cheerleader.
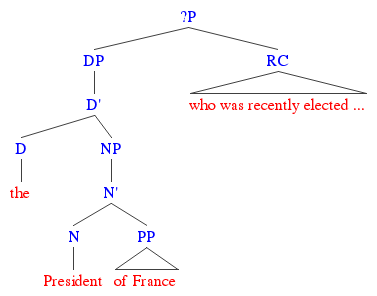
And non-restrictive relative clauses seem to be free of the influence of determiners. A sentence like “The President of France, who was recently elected to office, is relatively young” doesn’t seem to imply that there are a whole bunch of French Presidents, and that only one of them was recently elected; instead, the relative clause applies to everything that came before it — the whole of “the President of France,” including the definite article. So, we get a different picture of what these sorts of structures probably look like, with the non-restrictive relative clause attaching to some node sitting above the determiner phrase.
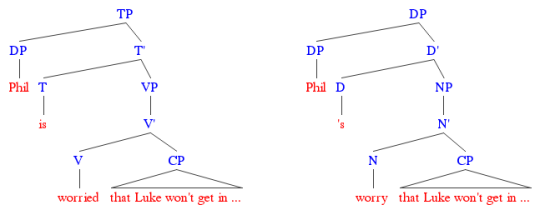
Finally, we see another brand of embedded clause that, on the surface, looks an awful lot like what we’ve seen already. Consider the following noun phrase:
(4) Phil’s worry that Luke won’t get into college
Notice, though, that unlike the relative clauses we’ve been seeing up until now, this one doesn’t have any gap in it; that is, it can stand on its own as a complete sentence.
(5) Luke won’t get into college.
These kinds of embedded clauses, which provide content to the nouns they modify, are known as complement clauses, because they look so much like the complements of verbs like “worry” and “claim” — found in full sentences like the one below.
(6) Phil’s worried that Luke won’t get into college.
And given their name, it seems reasonable to suppose they occupy a spot inside noun phrases that’s similar to the complements of these kinds of verbs, cozying up right next to the head of the phrase.
However, it turns out that this can’t quite be true. Not only are complement clauses able to follow restrictive relative clauses, it actually sounds kind of weird when they don’t! (And this is a pattern that holds across languages.)
(7a) I don’t believe the rumour that I heard this morning that he’ll move.
(7b) ??I don’t believe the rumour that he’ll move that I heard this morning.
Complement clauses even seem to work well after non-restrictive relative clauses.
(8) There’s a rumour, which I heard this morning, that he’ll be moving.
So complement clauses end up looking a lot like more some species of non-restrictive relative clauses than anything else (including real complements), meaning they probably connect up to a part of the tree that’s higher up than your average relative clause.
It really does take all kinds!
*Some insist on another difference between restrictive and non-restrictive relative clauses: that while either one may use relative pronouns like “who” or “where,” only restrictive relative clauses may use “that,” while only non-restrictive relative clauses may use “which.” But there are plenty of counter-examples to this supposed rule, as in Nietzsche’s famous quote “That which does not kill us makes us stronger.” And though non-restrictive relative clauses using “that” are very much an endangered species, they can still be spotted in the wild from time to time.
The subject of an English sentence sure looks like it starts off right at the top of the sentence. “Dan should play the lead” definitely seems to have Dan first. And yet, we’ve argued in past episodes that the participants in the activity that the verb represents start off inside the verb phrase. This helps explain why some languages seem to have both their subjects and objects showing up so low inside any given sentence. For example, in Welsh, the subject shows up between the verb and the object, suggesting it could be somewhere in the VP.
(1) Gwelodd Siôn ddraig
saw-3SGPST John dragon
‘John saw a dragon’
In English, the subject doesn’t stay down there; instead, it moves up into a higher part of the structure. Nevertheless, we can see that it sometimes leaves a bit of itself behind.
(2a) All the patients will [VP get better]
(2b) The patients will [VP all get better]
Now we’ve claimed in our most recent episode that, for both syntactic and semantic reasons, we shouldn’t visualize verb phrases as the monolith shown below, on the left. Instead, it’s better to think of the verb phrase as being split, into an upper part and a lower part. The lower half — the meat of the VP — contains the verb itself, and any objects that it needs to feel complete. The upper half consists of a kind of second verb phrase; it ends up encompassing the main one, not unlike how auxiliary and modal VPs sometimes do (e.g., “might have been switched”). And this new verbal region includes both the subject and, in languages with more well-rounded morphology, a special kind of affix that ties everything together.
But if you want to add in this structure, then you should probably expect to find some sentences without it, too. And we do!
So what does a sentence look like without this subject-introducing layer? Well, we should look for sentences that are short an agent— a doer to set the events described by the VP in motion. And when we search through our speech, it isn’t too long before we find just that.
One of the most familiar kinds of sentences that show up without an agent are passivesentences. With their familiar form of “be” and optional ‘by-phrase,’ their most notable feature is that they put their objects in subject position.
(3a) They took David’s sister.
(3b) David’s sister was taken.
And in our recent discussion on the relationship between active sentences and passive ones, we mentioned Burzio’s Generalization, which makes the observation that there’s a one-to-one connection between sentences that have no agent, and sentences which have no phrases marked with accusative case (e.g., the object pronoun “them” versus the subject “they”). We suggested this had something to do with the passive “be” and its accompanying affix “-en.” But when we get to chopping the verb phrase in two, we can develop a much more satisfying picture. To see how, let’s focus in on what the split really does.
In the episode, we said that one thing this new structure did was give ditransitive verbs like “put” some breathing room inside the lower VP, so that all objects — direct and indirect alike — could live in harmony.
Something else this does, though, is put the main object — which is something that normally shows up with accusative case (e.g., “put himin there”) — right beside our new, little ‘v’ and its agent-adding powers. And this puts us just a step away from understanding what’s going on: if we imagine for a moment that our little ‘v’ is in charge of adding agents and handing out accusative case to whatever’s right next to it, then we can ask what happens when it disappears.
Well, without little ‘v”, the agent for the sentence goes missing, and so does the ability to slap accusative case on anything! Two entirely separate things that shouldn’t really have anything to do with each other unexpectedly synch up, and we finally can make sense of Burzio’s Generalization. With that little ‘v’ pulling double duty, agents and accusatives actually go hand-in-hand.
Of course, passives aren’t the only sentences prone to pairing up with more object-like subjects. On top of alternating verbs like “roll” and “melt,” which we first used to introduce the idea of dividing things up, we find that some verbs alwaysarrive agent-free. In “He deteriorated,” “he” plays no real role in what’s happening, and if you try to use an active subject, it just sounds weird.
(4a) He deteriorated.
(4b) *They deteriorated him.
And raising verbs like “seem” and “appear” work along those same lines; they don’t come with subjects of their own, and sometimes even resort to stealing one from the following clause. Splitting the verb phrase now just means that these verbs come without an upper vP.
(5a) It seems he’s psychic.
(5b) He seems to be psychic.
Even straightforwardly transitive verbs like “eat” and “sell” can drop their agents under the right circumstances, showing off what’s sometimes called the ‘middle voice.’
So passive verbs, certain intransitives, and even ordinary transitives can, and sometimes must, appear without this outer layer, fitting snugly into our new paradigm. And some languages even flag when this new structure of ours shows up, in spite of its often stealthy character. Italian uses a separate set of auxiliary verbs when in the presence of a vP (“ha” for “have”), as opposed to when not (“è” for “be”). And a similar verbal scheme can be seen at work in German.
(7a) Maria ha telefonato
‘Maria has telephoned’
(7b) Maria è arrivata
‘Maria is arrived’
(8a) Die Maria hat telefoniert
‘Maria has telephoned’
(8b) Die Maria ist angekommen
‘Maria is arrived’
Thus, the structures underlying all languages emerge little by little, not only by way of English, but through the lens of languages arranged in ways that pull apart and shine light on these otherwise guarded secrets!
I gathered some experimental data asking people to form novel blends, and am resuming work analyzing that data. Here’s a Google Drive folder with the basic questionnaire I used, the five questionnaires I collected data on, and a spreadsheet of the data cleaned up. Feel free to examine if interested!
I have misguided all of you. The number of blends you can produce using the method I described in the last post is not N!; that’s the number of blends you can produce if you use every object in the set. The real number is much, much larger, and looks like this:
The number of ways you can take k objects from a set with N objects in it and order those combinations is equal to N!/(N-k)!, or the expression inside the big parentheses above. The weird shit on the left just says take that expression for every value of k from 1 to N and add the results all together. This is A Big Number. According to this helpful website, that number for 7 (like in mint plus sage) is 13,699. Compare 7!’s value of 5,040- more than double. 13! was equal to 6,227,020,800; the value of this function for N = 13 is 16,927,797,485. If I thought this method was a terrible way to make blends because it produced too many before, it’s much worse in reality.
Another of the of the ways in which ‘blends as permutations’ (well, k-permutations) model sucks is that there’s no guarantee that any given 'possible blend’ will contain material from both words. From mintand sage, both mintand sage are considered possible blends in this model! It’s a pretty solid generalization about blends that they contain elements from both words. How do we capture this in our model?
Well, let’s say that, instead of one bag, you have two- one for each word- and every time you have to draw a letter, you flip a coin. Heads means you draw from word A, tails means you draw from word B. You can only stop once you’ve drawn at least one sound from both bags (although you need not stop then), and for convenience’s sake let’s just say that once you’ve emptied one bag you stop flipping the coin and just draw from the other one. (An unintended consequence of introducing the flipping coin is that most of the time, the blends produced this way will contain roughly equal amounts of sounds from words A and B, but let’s ignore this for a second and just say that all possible blends are equally likely.)
How many blends can you produce in this way? Given what we learned above, this is pretty simple.
… where a is the number of sounds in A and b is the number of sounds in B. That is, the number of possible k-permutations of the sounds in A and B combined, minus all the k-permutations you can make from just the sounds in A and just the sounds in B. For mintand sage, this number is 13,620- 79 less than the above number. We’re getting somewhere, albeit slowly.
Scrapping the requirement that sounds from both words must end up in the blend, what about what sounds begin a blend? Seems like most blends start with a sound that starts one of the donor words, so let’s constrain the output to blends starting with a1 or b1. How many blends can we make in this way?
Well, let’s start with the set {1, 2, 3, 4, 5, 6, 7}, and say that the k-permutations all have to start with 7. There’s one permutation for k = 1 that fits this criterion- 7. After that, it’s 7 followed by every k-permutation of the set containing all the same members, except 7, as the set before- that is, every k-permutation of the set {1, 2, 3, 4, 5, 6}. So 1, for 7, plus every k-permutation of a set with 7-1 members.
So, if two members, a1 and b1, of a set of size N can start the k-permutations, the number is just double the above.
Let’s say you want to combine this requirement with the one above that both words must contribute to the blend!
This is getting ugly fast.
So here’s the golden question: Why am I counting all of these possible blends? Who on Earth cares how many of them exist? Here’s where I lay out my evil research plan:
I’m going to ask research subjects to form blends from various pairs of words, then compare the set of blends they collectively produce to the set of all possible blends under each of these models. And if models with certain constraints on them overgenerate less than the worst imaginable case to a statistically significant degree, we will have rigorously shown that those constraints meaningfully capture something about blend-formation in English.
Hello! It’s been more than a month, I bet some of you forgot that you followed this blog. If all goes well- cross your fingers for me, everybody- you should see a relative flurry of activity on this blog in the near future as I catch up with my backblog. (As you can tell, I chose the subject of blends for solely dry, academic reasons. … ‘Backblog.’ Hee hee.)
Today’s source is only the second I read for my independent study, whose midterm is fast approaching. Oops. It’s Louise Pound’s 1914 work, “Blends: Their relation to English word formation.” Like the Bergström source I looked at earlier, this one is out of copyright and is available for free and legal download here.
Pound’s work doesn’t say very much that Bergström didn’t, but she says it a lot better, and leaves a lot of silly things out. Even more excitingly for my purposes, Pound’s work is entirely about morphological blends, rather than being dedicated mostly to syntactic blends. If you’re only going to read one of these two works, read Pound.
The biggest new thing in Pound is that Pound introduces a source taxonomy- a taxonomy based on who made the blend and for what purpose. Pound divides blends into the following categories:
“Political Terms,” also including anything the press invents (e.g., gerrymander, Prohiblican, Popocrat)
“Nonce Blends” (e.g., sweedlefrom swindle+ wheedle), which is how Pound categorizes error blends, although she notes that error blends that prove popular may persist in the context in which they were accidentally coined. Apparently this label only applies to erroneous adults, because the next heading is
“Children’s Coinages” (e.g., snuddlefrom snuggle+ cuddle) which she notes as also largely accidental. (Why the split?)
“Conscious Folk Coinages” (e.g., solemncholy,sweatspiration) and
“Unconscious Folk Coinages” (e.g., diptherobiafrom diptheria+ hydrophobia, insinuendo), which are distinct from the conscious sort and from normal errors in that they are believed to be 'real’ words and have persisted in a wider context
“Coined Place Names; also Coined Personal Names” (e.g., Texarkana, Maybeth)
“Names for Articles of Merchandise” (e.g., Locomobile, electrolierfrom electro- and chandelier)
She notes that some of these aren’t mutually exclusive, and suggests that the source of a blend may affect its success; however, it’s not clear which she believes would be more successful. To me, this sort of taxonomy doesn’t seem very useful. I’m more interested in a taxonomy that references more linguistic characteristics of the blends and source words, but Pound essentially throws her hands up in defeat at taxonomizing blends in this way. Blends are too varied, she argues, for a “definite grouping [to seem] advisable.]”
She does mention that, as a hard rule, the primary stress in a blend is on one of the primarily stressed syllables from the source words, and she mentions haplology, which she describes as the deletion of one of two (or possibly more) similar syllables in sequence. A blend she describes as haplologic is swellegant, from swell+ elegant. The sequence /ɛl/, pronounced like the letter L, that would be repeated if you just said swell-elegant, is preserved only once. I wouldn’t necessarily describe the /ɛl/ in elegant as a syllable- I’d say that the /l/ starts the next syllable. In fact, many of the haplologic blends she describes delete similar sequences, and not properly syllables. Does this matter? You’re free to discuss among yourselves.
Pound, like Bergström, brings up onomatopoetic blends, and doesn’t conclusively place them in or out of the category of blends. I tend to say 'out’. Onomatopoetic 'blends’ generally have as their sources one of two classes of words that have sounds and maybe a general meaning in common and combines those sounds together; for instance, chump (with the original meaning 'a short segment of wood’) is suggested to have arisen from chop, chunk, or chuband lump (but equally plausible, and having similar meanings, are bumpand hump).
With no definite single-word source for either element, it seems more likely that a word like this arose from non-word, non-morpheme (it’s not like you can add -ump onto anything and make words referring to small, smooth raised areas on a surface) associations people have with certain sounds or sequences, so that words made 'out of the blue’ have suggestive forms. This, or ideas like it, is called sound symbolism- the apparent meaning individual sounds sometimes appear to have when the sounds themselves don’t behave like morphemes.
That’s about it for Pound (1914)- next up is MacKay (1972, 1973), a jump of nearly sixty years!
Or should I say, introbligatory? Obligatroduction? Perhaps I shouldn’t.
Hello all! My name is Matthew Aston Seaver, and I am a senior linguistics student at the University of Mary Washington. This semester I’m undertaking an independent study on morphological blends.
What’s a morphological blend?
Well, it can also be called a portmanteau, a blend-word, or just a blend- but fundamentally, a blend is a word like brunch- from breakfastand lunch- that is formed by fusing together two other words. What’s interesting about blends is that they are not a simple case of compoundingoraffixation. (An example of compounding is icehouse, from iceand house; an example of affixation is affixation, from affix, -ate, and -ion.) Both of those processes act on morphemes, the smallest units in language that can carry their own meanings. Morphemes can be bound, like affixes, and be unable to stand on their own, or they can be free, like independent words.
The thing to notice here is that neither *br- nor *-unch is a meaningful unit on its own. (In this context, the asterixes mean something like unattested, ungrammatical, or just plain wrong.) Because the units aren’t morphemes, traditional approaches to morphology- here, the inner structure of words- have trouble analyzing blends. Breakfast is meaningful, and so is lunch, but some of the material from both words is missing; what happened to ‘eakfast’ and 'l’?
For that matter, what about a word like slanguage (Irwin by way of Wood by way of Pound 1914), where slangand language both make it into the word intact? Or Lewis Carrol’s coinage slithyfrom slimyand lithe, where the words don’t even have the decency to occur linearly? Slimy wraps right around lithe- is that even allowed?
For my purposes- and this definition is subject to revision!- a blend is formed in such a way that there are at least two parent words, and in the output, there is no place where the end of one word is followed by the beginning of the other. You’ll notice in slanguage that the end of slang occurs well after the beginning of language, and that in slithy, lithe starts and ends entirely within the bounds of slimy.
Well, now that we’ve got that all cleared up, what’s left for me to talk about for this whole semester? I have a sneaking suspicion that there’s gonna be a whole lot.
It’s not often that a horror movie manages to snag the top spot at the box office, and even rarer that it should reclaim first place in its third weekend, after having dropped down to number two. But that’s exactly what John Krasinki’s new film A Quiet Place pulled off, to the tune of a 50 million dollar opening, and over 200 million worldwide. What’s more remarkable, though, is that such a mainstream movie would commit so steadfastly to its premise — where any sound made can attract the attention of deadly monsters — and silently render almost every word of dialogue in American Sign Language (ASL). And as a result, actress Millicent Simmonds explains, the film winds up being especially significant for the deaf community.
Simmonds, who is deaf herself, actually spent time on set helping the other actors learn ASL, which generally goes underrepresented in mainstream cinema. And the importance of casting a deaf actor and using genuine sign language is something she’s been quick to underscore. “I think it’s important in the deaf community to advocate for and be a representative for this story,” she says, “a story that might inspire directors and other screenwriters to include more deaf talent and be more creative in the way you use deaf talent.” “What I hope is that I can show [my community] you can do anything,“ she goes on to explain, “not only become an actor, but a writer, a teacher, a pilot, anything you want to do is possible.”
And for those who’ve now seen the film, there’s yet another linguisticky easter egg to be found, around which the whole final act of the movie turns. So if you don’t want to be spoiled, be sure to stop reading right now, because principle plot points abound below the fold! ^_^
So, as the fast-paced story comes to its close, the characters discover that the sound-hunting monsters’ weakness is, fittingly, the very device that Simmonds’ character Regan uses to help her hear. But the detail that filmgoers seem to have missed is exactly what’s happening in those final few minutes before the credits. Manyreviewers seem to have taken Regan to be wearing a conventional hearing aid, and have gone on to assume that the evil invaders induce a sound in it that both Regan and them found too painful to bear, giving our heroes some hope for the future. But you might have noticed that part of Regan’s equipment attaches to just behind her ear, as if by magnet. In fact, this is because she’s not using a standard hearing aid at all, but a cochlear implant, which doesn’t actually have the capacity to produce sound, seemingly opening up an enormous hole in the middle of the film’s plot!
Specifically, hearing aids contain both a microphone and a speaker, amplifying the sounds around a wearer and broadcasting them down the ear canal. But for those who have suffered severe damage to the cells inside the inner ear, which are responsible for processing that sound, amplification isn’t enough; the receiver simply isn’t operating, and no level of volume will do the trick. With a cochlear implant, electrical signals are transmitted directly into the cochlea instead, which contains a special membrane. And as I mentioned in another post about the inner workings of the ear, this membrane acts a tonotopic map, which means that different locations correspond to different frequencies. And so it follows that a direct electrical signal can cause a wearer to experience different sounds — at least, enough to perceive and understand speech.
But if cochlear implants don’t produce any audible sound, doesn’t the whole movie fall apart? Not quite, thanks to the filmmakers being clever enough to provide all we need to work out what’s really going on.
If you pay close enough attention, you might have noticed that every time the creatures come around, the lights flicker off and on. This strongly suggests they produce some kind of electrical field, maybe as a result of having electroreception, like a shark. In other words, they use their own electrical field, and its tendency to interact with the surroundings, to locate their prey in space (this would be on top of their remarkable hearing). This is made most obvious when one of them angrily attacks an old CRT monitor displaying static; as this handy explainer makes clear, the static we see is just the ambient electromagnetic radiation being translated into an image of a snowy mess. Which means the creature is reacting to its own body’s signal fed back to it. And if that same electrical field can induce a reaction in a cochlear implant, which goes on to generate its own electrical signal in response, the implant might be able to irritate the monster as much as the TV did. In other words, it isn’t really sound at all that ends up making the difference.
(One potential problem with this theory is that Regan seems to triumphantly dispatch the monster’s protective armour by holding the external part of her implant up to a microphone, apparently amplifying its sound — a sound that should’t even exist! But this becomes less of an issue when we remember that any device that’s capable of producing an electrical signal has the potential to interfere with audio equipment. For instance, just think about the interference you hear when your cell phone goes off near a set of speakers. And, so, it isn’t so much the sound that matters, but the creature’s own electrical signal being amplified back towards it.)
So the invaders’ Achilles’ heel isn’t so straightforward after all, which also probably helps explain why they took over so quickly. In the end, though, a healthy mix of physics, biology, and linguistics come together to save the day! :-O
Thus July, the International Linguistics Olympiad (a problem-solving competition aimed at secondary school students) will be held in Dublin. Since I’ve been helping a bit to organize the French half of this year′s Canadian Linguistics Olympiad – which leads directly into the international event – I figured I’d share some of the relevant details here, in case you (or someone you know) might be interested in participating!
So, if you like riddles, love language, or just really need to get to Ireland, be sure to share this advert!
On Thursday, January 19th, there’ll be an info session at l’Université du Québec à Montréal (UQAM), with the competition itself happening at the end of this month. No previous training is needed, but a love of puzzles definitely helps!
The Language Conservancy does a lot of really interesting and amazing work for helping revitalize and raise awareness about Native American languages, and they’re worthy of your time and support, even outside the P4A. Check out their website, which has a ton of info about their activities.
If you don’t know about the Project for Awesome, it’s a yearly charity and awareness raising campaign on YouTube aimed at decreasing world suck. Find out more, and vote for videos, at the P4A site!
In the past few years, a number of films have made a point of Getting the Science Right. Interstellar (2014) famously consulted with astrophysicist Kip Thorne, in order to achieve a realistic on-screen depiction of black holes (amongst other things). Just last year, The Martian was praised for basing much of its appeal around its scientific realism.
Now, in 2016, the sci-fi film Arrival is attracting similar accolades for it’s portrayal of linguistics, and of how scientists approach solving a problem. One standout piece hails from Science vs. Cinema – a YouTube channel devoted to examining how Hollywood fares on various science-related matters:
Since the movie only had so much time to cover exactly how Amy Adams’ character Dr. Louise Banks unraveled the aliens’ writing system, let’s do a deep dive and actually answer the question:
How do linguists do what they do?
So, the short answer is pattern recognition. Just like how a physicist might toss a ball up into the air a bunch of times to figure out which rules it follows coming down (or toss some baryons at each other to see what comes out the other side), a linguist will observe how the sounds and symbols of a language regularly connect up to meaning. With even a small amount of data, a linguist can begin the process of uncovering the relationships that hold between speech and the world it’s used to represent.
What does this look like? Well, we don’t have any real alien languages to work with (for now), but we’ve got plenty of human languages to choose from – between six and seven thousand. So, let’s pick one, look at a few examples, and see what we find!
To get as far away from English as we can, let’s go to Kashaya – an endangered Pomoan language spoken in California. Unlike English, which is analytic and tends to keep its morpheme-to-word ratio low (relying heavily on word order to keep track of who’s doing what to whom), Kashaya is polysynthetic; it tends to pack lots of information into each word, by way of affixation, and has relatively free word order.
Now, about half the world’s languages don’t have any developed writing system associated with them; with those that do, many lack native representation, relying instead on some version of the Latin alphabet. Kashaya is one such language, with its written form having been developed by Dr. Robert Oswalt in the 1960s. In the examples that follow, you can think of each word as being written in a kind of quasi-IPA; the words on the left represent the actual sounds of the language, as understood and transcribed by a linguist, while the meanings hang in the right-hand column.
bahcúw
‘to jump’
bahcubedu
‘always jumps’
coqocedu
‘always shoots’
coqów
‘to shoot’
kelci
‘peek!’
kelcíw
'to peek’
coqo
‘shoot!’
(At this point, I should admit I grabbed this data from a linguistics assignment. In the context of the film, the Heptapod language doesn’t come with an instruction manual, so Louise has to employ a monolingual demonstration – a technique used to elicit linguistic data when no common tongue exists between the parties involved. If you want to see this in action [you do], I highly recommend having a look here. In under 40 minutes, and without any assistance, linguist Dan Everett works with a speaker of a language he has no knowledge of and manages to uncover basic facts about its word order, sound inventory, and morphology. It’s really an impressive thing to behold, even for other linguists.)
Let’s start by choosing two words which share some meaning, to see if we can figure out what else they have in common. Beginning with the words for ‘to jump’ and ‘always jumps,’ we might tentatively conclude that what they share – “bahc” – means ‘jump,’ and that “úw” and “ubedu” mark the verb as being tenseless andhabitual, respectively. But throwing a third word into the mix – “coqocedu” for ‘always shoots’ – forces us to either reject or revise our hypothesis; “ubedu” can’t mean ‘always,’ since the only common sounds between the second and third words are “edu.” What can we do?
Here, it helps to know a bit about what languages sometimes have up their sleeves. In this case, it’s important to notice that the first consonants – “b” and “c” – are repeated in “bahcubedu” and “coqocedu.” This looks like reduplication, which involves the repetition of some or all of a root word, sometimes with some modification. It’s not as exotic as it sounds, since English speakers use this strategy when treating something dismissively (e.g., “alien-shmalien”). So, Kashaya might instead express ‘always’ using partial reduplication, followed up with “edu.” We’d need more data to know for sure, but it’s a good start.
As for those shifting vowels – “bahcubedu” vs. “coqocedu”? Maybe they’re not part of the the affixes, after all; maybe they’re part of the verb! In fact, the fourth word – “coqów” – seems to confirm this, since they each tend to stick to one verb root pretty consistently. Which means we need to say something more about that tenseless marker: it’s really just a “w,” with some stress added onto the last syllable. And, again, it’s not so unusual for stress to play a role in grammar; “complex” can mean either “complicated” or “a bunch of buildings,” depending on where you put the main emphasis.
Looking at the rest of the list, we can add that the absence of an affix altogether apparently marks the verb as imperative, meaning it can be used to issue a command. So, all in all, just 7 words have told us something about the sounds used in Kashaya, whether or not it has stress and reduplication, how to mark verbs as tenseless, habitual, or imperative, and how to say “jump,” “shoot,” and “peek.” Not bad, eh?
And this is just how Louise approaches Heptapod B, the film’s alien writing system. You can see for yourself, in this behind-the-scenes snapshot, that each logogram can be divided up into 12 segments. (Having an upper limit to sentences isn’t something you really see in human language, but of course this isn’t a human language!)
Looking closer, we can see the kinds of patterns we’d need to pay attention to, to begin cracking open the language. In the image below, the lowest righthand portion is shared across both logograms. (Actually, the bottom twelfth is the same across both of them, too. Maybe, like in Kashaya, this absence communicates something meaningful!)
And armed with this understanding, Louise devises a program to automatically analyze the logograms’ parts.
She even reverses the process by taking that database of segments and using it to construct her own logograms, in order to pose the all-important questions at the heart of the story.
Too cool!
It’s encouraging that the movie managed to capture the process so well (if only briefly), and it’s impressive that it’s resonated with audiences so much. I know I speak for more that just myself when I dare to hope this means we’ll be seeing more of a willingness on moviemakers’ parts to represent real science on the big screen. It might’ve sounded farfetched to say so just a few years ago, but a little linguistics in Hollywood seems not to be such an out-of-this-wolrd idea, after all!
If you enjoyed this story, and want to learn more about the linguists who worked on Arrival, definitely have a look at this!
And if you happen to be a student at the University of Pennsylvania, and you’re interested in helping to document and preserve endangered languages like Kashaya, be sure to check out the work being done by Professor Eugene Buckley, here! No experience needed!
While it is perhaps unfortunate that we do not know the meaning of some Etruscan words, it does result in several gems when an author simply italicises an untranslatable word in the gloss and translation:
Flere in crapsti
Divinity which in crap
“divinity, which [is] in crap”
Flereś crapśti
“of the divinity in the crap”
(Etruscan is an ancient language that was spoken and written primarily in northwest central Italy. It is also a language isolate meaning, with a few exceptions, it is unrelated to any known language ancient or modern. The alphabet used for Etruscan is based on the Greek alphabet, which means scholars are able to read many of the texts. Working out what they mean, however, is essentially informed guesswork. Check out Helmut Rix’s chapter on Etruscan in The Cambridge Encyclopedia of the World’s Ancient Languages, for more examples and information!).
I have just finished reading Lenneberg’s 1967 seminal book The Biological Foundations of Language. It was, and still is, an incredibly insightful attempt to bring linguistics and biology closer together into what is currently called biolinguistics. It was also way ahead of its time in terms of the conceptual framework which underpins the biological theory of language proposed in the book. By amassing and integrating evidence from anatomy, neurology, cognitive science, evolutionary theory, developmental biology, child language acquisition, semantics, phonology and syntax, Lenneberg creates a theory of language based on a few far-reaching principles.
First, language is viewed as a species-specific behaviour. Every species is different in terms of how they develop and mature. To the extent that behaviour is based on neurophysiological properties of the organism and that neurophysiology is a product of species-specific paths of development and maturation, language can be considered a species-specific behaviour resulting from the human-specific ontogenetic process. Evidence for this includes well-documented and universal milestones in language development, sometimes even in the absence of appropriate linguistic stimuli.
Second, there does not appear to be any part of the brain dedicated to language. Certainly, there are regions of the brain (and particularly of the left hemisphere) which play a more significant role in language, but in general language is well-integrated into the cerebral structure as a whole. This makes it likely that language evolved from the outset as a complex integration of many parts; it is unlikely that the subcomponents of language evolved separately and only recently became unified.
Third, language structure exhibits evidence of three basic processes: (1) categorisation, (2) differentiation, and (3) transformation. Categorisation involves generalising over stimuli, i.e. creating an abstract representation. Differentiation involves splitting categories in various ways. Transformation involves being able to identify similarities between categories, i.e. being able to identify how one category is related to another in a systematic way. Lenneberg argues that these are cognitive skills which have been integrated into the structure of language. Furthermore, because every infant effectively creates language anew, these are the processes involved in language acquisition, for example, early child utterances go through a one-word stage, followed by a two-word stage, then simple sentences etc. This potentially shows differentiation in that one-word utterances are whole child sentences. As the child differentiates the earliest syntactic category into two (say, head and modifier), we begin to observe two-word utterances etc.
Fourth, environmental triggers are necessary for the proper actualisation of one’s innate potential for language. These triggers must be available during maturation otherwise the behaviour will not develop properly, i.e. there is a critical period for (first) language acquisition. The acquisition of language is thus a matter of nature and nurture, innateness andlearning.
There are other principles which Lenneberg summarises in the final chapter, but these give a flavour of the framework in which his theory is set. Language is at its foundations a biological phenomenon, and biolinguistics can help us formulate and pursue questions to understand it in a more insightful and informed way.