#morphological blends


blends is the same
I gathered some experimental data asking people to form novel blends, and am resuming work analyzing that data. Here’s a Google Drive folder with the basic questionnaire I used, the five questionnaires I collected data on, and a spreadsheet of the data cleaned up. Feel free to examine if interested!
I hope you were not misled by my last posting; most of this blog is going to be me explicating and responding to scholarship on blends, and not fun examples of blends in pop culture, although I’ll try to post any of those I find! I do hope, however, to keep these posts as digestible and accessible as possible.
Today’s post concerns the chronologically earliest source I found in my initial research, “On blendings of synonymous or cognate expressions in English,” a 1906 dissertation by one Gustav Adolf Bergström, which is out of copyright- you can download it freely and legally here. (By the way, you will find a full citation of any academic source I mention here on the References page, which can be found on the sidebar of my blog.)
This text has a couple of issues. One, it’s one of the worst-organized pieces of scholarship I’ve ever read- sorry, Gustav. (In his defense, he says in his preface that his work got derailed by illness, which I totally get.) Two, Gustav considers the primary focus of his work to be what he calls ‘syntactic blending,’ where a speaker appears to have started saying one sentence or phrase and then meandered into another, and while he considers lexical blends to be related it’s a secondary focus of the work.
I don’t like this idea that 'syntactic blends’ are related to morphological blends at all! Current theories of linguistics that I’m familiar with say that there is a two-way split, roughly, in the representation of language in the mind. On the one hand there’s the lexicon, which is like a mental dictionary that stores everything you know about all the words you know- their form(s), like the fact that to be has the present-tense indicative forms am,is, and are, their syntactic category, such as verb, noun, adjective, etc., and their meaning, although it’s controversial exactly how much information about a word’s meaning is stored in the lexicon. On the other hand there’s the syntactic component, which strings words together according to certain rules. (You can go into finer detail about how the syntactic component is divided, but I won’t here.)
The point being, words are stored in the lexicon, but phrases and sentences are built in the syntactic component from words in the lexicon, and not 'stored’ in the same sense as words are stored (with the exception of idioms, phrases or sentences whose meanings are memorized rather than being possible to figure out just from the words they’re made up of- for instance, letting the cat out of the bag means 'telling a secret,’ which isn’t obvious at first glance and which language learners have to memorize). So words and phrases/sentences are very different things, structurally- one memorized, one constructed on the fly.
Bergström’s theory about how error blends, blends formed on accident as a speech error, are formed is that the speaker considers two related words at once for a given thought and tries to articulate both- or, more precisely, switches over at some point from saying one word to trying to say the other. As far as psycholinguistic theories from before the cognitive revolution go, this isn’t bad! It’s hard to say, though, that the same process applies to 'syntactic blendings’ when our theories say that phrases aren’t stored in the brain in the same way that words are- even if people do consider two different phrases at once and accidentally switch between them, they’re constructing them in the moment instead of simply remembering them.
Since I’m studying morphological blends specifically, and I don’t agree that 'syntactic blendings’ are another instance of the same phenomenon, I didn’t make use of the parts of the text that were about these 'syntactic blendings’.
Despite his focus not being on morphological blends specifically, he does have some interesting insights to offer. He suggests that blends are asymmetric, that is, that the two words that contribute to a blend may contribute to it in different ways. While he doesn’t go into much detail about how their roles may differ, this basic insight will, as we’ll see later in the semester, be borne out by more modern research. He notes, as other researchers have, that blends occur in many (perhaps all) languages- that is, they are cross-linguistic. And he theorizes that error blends result from pairs of words that are related in meaning through synonymy, similarity or equivalence of meaning, or antonymy, opposition of meaning. Intentional blends, which are what they sound like- blends made on purpose- he suggests are in imitation of naturally-occurring error blends, and don’t have to be synonyms or antonyms like error blends do. He specifically mentions that two words that are frequently right next to each other may be blended intentionally, such as GritainfromGreat+Britain.
He notes that some blends seem 'better’ than others, a concept for which I often use the term felicity- literally meaning 'happiness’ or the quality of being pleasing. This is a difficult-to-define concept, but basically it means how 'successful’ a linguistic form is in some measurable way- how easy it is to understand, how likely it is to be adopted into the mainstream, or simply how much speakers prefer it to other, similar forms. I did a pilot study a while back on what factors make unfamiliar blends more easily intelligible to speakers, which I might make the subject of another post.
The qualities that Bergström suggests may influence the 'success’ of a blend include usefulness (does the new form encapsulate some common concept that is otherwise complicated to express?), whether the blend fits the 'character’ of the language (which I’d translate into, does it sound like other commonly-used words?), and the frequency of the parent words separately and together.
It is because of lack of this 'success’ in making it into the mainstream that blends are such a comparatively rare source for new words in the general knowledge; he suggests that blends are invented all the time, but rarely make it out of the small circle in which they were innovated, so that they die out almost as fast as they’re invented.
Bergström also notes some commonalities in form among blends- that they preserve stress on one of the stressed vowels in the parent words. For instance, in the blend Brangelina, it's Brangelina, and not Brangelinaor Brangelina; it takes its stress from the source word Angelina. He further notes that both beginnings of words are rarely preserved, but does not note that, to my knowledge, it is never the case that neither beginning is kept. Finally, he makes a chart that I’d be better off inserting as an image than trying to describe:
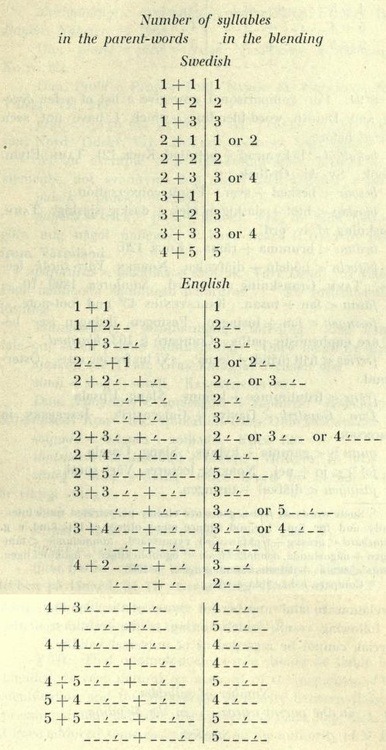
Fig. 1: Bergström takes the blends he has available and compares the syllable number and stress position of the parent words to the syllable number and stress position of the blend. In the English chart, each underscore represents a syllable and the tick mark represents the syllable that takes primary stress.
Finally, Bergström divides blends up in several ways- that is, he forms a taxonomy, or a system that divides things (here, blends) into groups based on characteristics they all share. The first major taxonomy he introduces is three-way: 'subtractive compromises,’ where both parent words lose material in the blend, like brunch; 'partial subtraction compromises,’ where one word is preserved but the other loses material, like slithy; and 'addition compromises’, where neither parent word loses material. For the last category, he uses the example forbecause, which just sounds to me like a compound; for my purposes, I’d say this would apply to a word like slanguage.
He additionally divides blends into one category that switches from one word to the other only once- like brunch, where br- is from breakfast and then it switches to -unchfromlunch- and another category that switches between the words more than once- like slithy, with the sl- from slimy, -lith- from lithe, and the -yfromslimy once more.
The last division Bergström makes is between error blends and intentional blends, which we’ve talked about already, and onomatopoeia blends. Onomatopoeia are 'sound-imitative’ words like bangandclick, and frequently words of this type that mean similar things have similar sounds in them. Here Bergström classifies some of these as blends, as will the next source I examine- Pound (1914)- but I incline towards a different analysis which I will expand on after writing about that source.
Whew! That’s a lot of words! Buckle your seatbelts, kiddoes, because posts like this are gonna make up the meat of this blog.