#psycholinguistics

You know how articles reporting on psycholinguistic experiments often say something like ‘X number of people took part but Y number of people’s results were discounted for various reasons…didn’t understand the instructions, wasn’t paying attention, was generally incompetent…’, well now I can say I have probably just been admitted to that inevitable and illustrious group of rejected data-providers.
First, I did some example tests to get used to the computer and the instructions for the task which involved learning a made-up language. That was all well and good. Then I started the experiment proper. I was plugging away at the exercises, tapping here, tapping there as required until the researcher came in mid-way and told me, in a kindly, roundabout sort of way, that I was being too slow (it was meant to be a short-term memory test after all)!
After that, I sped up as best I could. After the first short-term memory part, I moved on to the second long-term memory one. Essentially they were testing to see what kinds of rules I had learned from part 1. After the experiment there was a quick interview-like section where the experimenter asked me to describe the rules I had learned from the exercises and what I thought this made-up language was. Now here’s the bizarre bit…I correctly spotted that the made-up language was essentially an ergative language - hooray! However, virtually all the rules that I had been using during the experiment (and consequently my answers) were completely wrong!
It turns out they are testing whether certain alignments (e.g. ergative alignment or accusative alignment or some unattested one) are equally learnable or not. I reckon their null hypothesis will be that unattested and attested systems are equally learnable with the aim of demonstrating that typologically-unattested systems are harder to learn. Evidently I find even attested systems hard to learn! I suppose (and hope, for dignity’s sake!) that in every experiment there’s always one such person!
I just realised that if someone can read your mind, but you think in a language they don’t speak, then you still win. And this is why you should learn more languages, kids. So the CIA can’t track your brain-thoughts.
That is, if thought is linguistic. If mind readers work more like a babelfish or a brain scan, they read the thoughts regardless of the language (or not) they are in.
Right! Most thought is non-linguistic, so I don’t think you could actually hide your thoughts from a mind reader. Unless you would consciously try to only think in words, then maybe.
Psycholinguistics - Crash Course Linguistics #11
We couldn’t have language without the brain, but our brains are a bit harder to study than other parts of the body that we use to make languages like our mouths and hands. In this episode of Crash Course Linguistics, we’ll learn about the field that studies where and how language happens in the brain, called psycholinguistics. We’ll cover old and new research in the field, classic studies, and the methods psycholinguists use to uncover the connections between language and the brain.
For more psycholinguistics, check out this week’s issue of Mutual Intelligibility.
The comparative sentences that we talked about in our episode on grammatical illusions, like in (1) below, are surprising because of how far away people’s first impressions tend to sit from reality.
(1) More people have been to Montreal than you have.
When you give it a moment’s thought, it becomes clear there’s a sizeable gap between how sensible it seems at first glance, and how little information it actually communicates.
Even the illusory sentence in (2a) below, which was rated in experiments as being nearly as acceptable as the perfectly ordinary sentence in (2b), still falls apart when you try to put its pieces together. Spelled out, its meaning ends up as something like “how many girls ate pizza is greater than how many we ate pizza,” which doesn’t quite work; pronouns, even plural ones like “we,” can’t easily be combined with counting expressions like “how many.”
(2a) More girls ate pizza than we did
(2b) More girls ate pizza than boys did
But we still manage to interpret these sentences, in a way that fits the machinery made available by our mental grammar. As we discussed in the episode, the fact that we’re also able to count how many times something happened, in addition to how many there are of something, gives us a kind of half-working backdoor into understanding them. But, there’s another kind of illusion that’s even more striking, where there really isn’t any way at all to make sense of it. Try reading the following sentence aloud.
(3) The patient the nurse the clinic had hired met Jack
It seems pretty run-of-the-mill, pretty boring … except when you try to work out who’s doing what to who! It’s clear enough that the patient met Jack, and that the clinic’s doing some hiring, but what’s that nurse doing in the sentence? What’s his or her relationship with the patient? Or Jack? The nurse is just kind of … floating there, not really doing anything at all!
To make what’s going wrong more obvious, have a look at the simplified structure below. Each clause, whether it’s the overall sentence or an embedded one, has to have one subject noun phrase and one predicate verb phrase. Three clauses means three of each, but plainly, one of the verbs is simply missing in action!
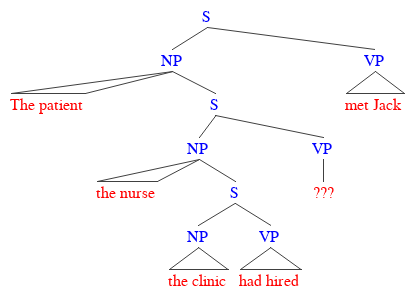
This problem becomes unavoidable when we trim our tree and take out that lowest clause, giving us “The patient the nurse met Jack,” which really can’t mean much of anything. In fact, it’s a violation of a basic condition on the shape that sentences can take, known as the Theta Criterion, which essentially demands that verbs and their subjects have to match up one-to-one.
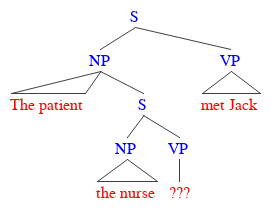
Sentences like the one in (3), then, end up forming a class of grammatical illusions that result from the so-called missing-VP effect. And as remarkable as they might seem already, things get even stranger when we consider their supposedly grammatical counterparts. Take the modified version below, with the missing VP put back in its place.
(6) The patient the nurse the clinic had hired admitted met Jack
While everything’s where it should be, the sentence has now become just about impossible to follow — or, at least, a lot harder to understand on a first pass than the simplified version in (7), where the lowest clause has once again been pruned from the tree.
(7) The patient the nurse admitted met Jack
This difficulty with understanding an otherwise perfectly grammatical sentence — at least, according to the rules we know about — is thanks to a phenomenon that’s been pondered over since at least the 1960s: centre embedding. While placing one clause right in the middle of another works fine once, as in (7), applying the same rule a second time over produces an incomprehensible mess, like in (6) above or (8) below.
(8) The dog that the cat that the man bought scratched ran away
Even though we can diagram these sentences out and force ourselves to follow the plot from one branch to the next with a whole lot of effort, they don’t really sit well when we hear them out loud. And this seems to suggest an upper limit on how many times our rules can apply. Except, we can find cases where this upper limit goes right out the window, like this 3-clause deep sentence!
(9) The reporter who everyone (that) I met trusts said the president won’t resign yet
With a quantifying expression and a pronoun in place of two more definite noun phrases, everything seems to be back in working order. And even more complex sentences than this can be found in writing, though they’re fairly rare.
So, what’s going on here? And how can we account for all this seemingly contradictory data? To start, it’s worth considering one of the most cited papers in all of psychology, The Magical Number Seven, Plus or Minus Two by George A. Miller. This work became famous not for putting an upper limit on how many times some rule or other could apply, but on how much information we’re able to hold in working memory. Like the title says, there seems to be a fairly low ceiling on how many ‘bits’ or ‘chunks’ we can actively hold in our heads at any given time. And this applies to processing language as much as anything else.
In fact, in a pair of papers co-written with linguist Noam Chomsky the following decade, Miller hypothesized that our trouble with centre embedding has more to do with limitations on our memory than on our grammar — which could account for why fiddling with the details (e.g. swapping certain kinds of nouns for others) can sometimes get around the problem.
But then, what exactly is going wrong in the sentence in (6), and more importantly, why should something meaningless like (3) get a free pass? Well, research into how we handle these sentences is very much active, but at least one recent theory takes some steps towards shedding a little light on the contrast.
As we encounter each new noun phrase in a sentence like (3), an expectation is set up that we’ll reach the end of that clause; in other words, we anticipate that we’ll encounter a matching verb phrase for each one. But something starts going wrong when we get to the lowest, most deeply embedded part of the sentence (i.e., “the clinic”).
When we hear that first verb phrase “had hired,” it slots into the lowest open position pretty easily, because that lowest and most recently encountered clause is the current focus of our attention. But when we encounter that second verb phrase, “met Jack,” we’re left at a disadvantage: we’ve got two more open positions to fill, but each one completes a clause that’s been interrupted by another one, having had the focus of attention wrenched away from it. What’s worse, all the clauses are syntactically identical, with nothing to differentiate between them. And, so, the little working memory we have is overloaded. We default to connecting that second verb phrase to the first, highest clause, and mistakenly assume we’ve finished building the sentence.
This Interference Account supposes that the two remaining incomplete clauses that were interrupted by an intervening relative clause compete and interfere with each other, overwhelming our limited memory and forcing us into making the wrong choice. It also explains why we have so much difficulty with centre embedding more generally: since we default to connecting that second verb phrase up to the highest clause, believing we’ve completed the sentence as a whole, encountering a third verb phrase in a sentence like (6) or (8) completely violates our expectations, and throws us for a loop.
So, the existence of acceptable nonsense like (3) and of well-formed but incomprehensible sentences like (6) doesn’t mean that our grammar is broken beyond repair; it just means that the rules that make up language are owned and operated by less-than-perfect users!
How do some sentences trick us into thinking they’re good, when really they’re not? And what can that tell us about how we process language? In this week’s video, we take a look at the comparative illusion, a tricky kind of sentence that seems meaningful, but falls apart when we consider it further. And then we look at what exactly it is about them that confuses our minds.
This is a shorter format video that we’d been toying with making for a while! Do you like this length? We’ll be making more of our regular length videos coming up soon!

Orthographic depth
Languages have different levels of othographic depth, that means that a language’s orthography can vary in a spectrum of a very irregular and complex orthography (deep orthography) to a completely regular and simple one (shallow orthography).
English, French, Danish, Swedish, Arabic, Urdu, Tibetan, Burmese, Thai, Khmer, Lao, Chinese, and Japanese have orthographies that are highly irregular, complex and where sounds cannot be predicted from the spelling. These writing systems are more difficuld and slow to be learned by children, who may take years. In the medium of the scale there’s Spanish, Portuguese, German, Polish, Greek, Russian, Persian, Hindi, Korean, where there are some irregularities but overall the correspondence of one sound to one phoneme is not that bad. At the positive end of the scale there’s Italian, Serbo-Croat, Romanian, Finnish, Basque, Turkish, Indonesian, Quechua, Ayamara, Guarani, Mayan languages, and most African languages (because there were no history of spelling, so a new one of scratch was made as very regular), they all have very simple and regular spelling systems, with usually a one-to-one correspondence between sounds and letters. These are very easily learned by children.
Orthographic depth has several implications for the study of psycholinguistics and the study of language processing and also acquisition of reading and writing by children.
Note: remember that there’s no objective numbering on the three categories I made, there are more than just these three categories, because it works like a spectrum. Three categories were used just as a means for simplification.
Post link