When people study language typology they study the ways in which languages vary. However, it’s more than just saying different languages use different words or these languages use very similar sounds. We study the ways in which structural features of languages differ (or are similar) and many go further asking questions about what the limits of linguistic structural variation are.
English speakers will know that in a simple transitive clause we start with the subject followed by the verb followed by the object, e.g. ‘Bob (S = subject) likes (V = verb) pizza (O = object)’, i.e. English has typically SVO word order. But are there other ways of arranging such a structure? Logically there are six ways: SVO, SOV, VSO, VOS, OSV, OVS. The next question that a typologist will ask is how are languages distributed across these possibilities. As a null hypothesis we might think that we would expect to find roughly equal numbers of languages in each group, but this is not what we find at all. SVO and SOV account for around 85% of all languages (with SOV being a bit more frequent than SVO). Adding VSO languages brings the total to around 95% of all languages. The question is: why is the distribution of languages so skewed?
Three broad types of answers suggest themselves as candidates (at least to my mind):
1) It could be down to chance – the distribution of languages today may represent a highly skewed sample. If we came back in 1,000 years we might see a completely different distribution. This approach is obviously not taken by language typologists. There is certainly something interesting about the distribution which demands an explanation. To write the pattern off as due to chance would be to miss potentially significant insights into the ways languages are structured and shaped.
2) The formal aspects of human language (perhaps as encoded by Universal Grammar) constrain the surface forms that human languages can inevitably take, i.e. variation is not limitless though it may be apparently vast.
3) The functional pressures that act on speakers and hearers every time they use language will affect which forms languages will prefer to take, i.e. structures that are easier to say and to comprehend will be preferred and so will come to dominate amongst the languages of the world.
Given the great success of generative linguistics in the past few decades, (2) is a very popular approach to take. However, many intuitively feel that the approach in (3) is ultimately more satisfactory as an explanation. Personally I’m inclined to think that if we can explain surface variation in terms of performance preferences, this is a good thing because it means there is less for the formal approach to account for. Furthermore formal aspects of language are most often thought to be all-or-nothing affairs. If a grammar rules out a particular structure, that structure cannot exist, whereas if performance factors disfavour a particular structure, that structure will be either non-existent or rare.
But are (2) and (3) incompatible? You might think so given the distinction that’s often made between competence and performance. Many would not consider performance factors as relating to language proper – it is extra-linguistic and not something the linguist should be looking at. But the fact is that all the (overt) language that we use to construct theories of both competence and performance is being ‘performed’ in some way (either spoken or written or signed). I think there may well be limits on variation set by formal properties of human languages (which will account for some of the totally unattested structures) but others will be set by performance. And then maybe others that are to do with physics and biology more generally (here I’m thinking more of phonological typological patterns).
For now then it may be useful to adopt either (2) or (3) as an approach to language typology with the aim of seeing how far they can go, but always with the ultimate aim of putting the two together in the end for a more comprehensive account of why languages are the way they are.
The words for ‘one hundred’ in Indo-European languages exemplify an ancient sound change – the centum/satem split (the Latin and Avestan words for ‘one hundred’ respectively).
Proto-Indo-European has been reconstructed as having three ‘series’ of velar consonants – palatal velars, plain velars and labiovelars (*kj, *k and *kw respectively). However, in nearly all daughter languages, these three series collapsed into two. Languages on the centum-side of the split merged the palatal and plain series to be left with *k and *kw and those on the satem-side merged the labiovelars and plain series to give *kj and *k.
It was thought to be the case that the centum/satem split represented an ancient dialect division of Indo-European languages. Most centum-languages are found in the west whilst most satem-languages are found in the east. However, a number of problems with this view exist. Tocharian is a centum-language but is (or was) the furthest east of any Indo-European language. There is also evidence that some languages kept the three series distinct in certain environments longer than others, e.g. Luvian (an extinct IE language spoken in Anatolia).
This, plus other evidence, suggests that the centum/satem labels are better viewed as descriptive shorthands which are used to label mergers which occurred independently in various Indo-European daughter languages (although this view raises problems of its own as well!).
Grimm’s Law was highly successful at predicting the forms of Germanic words but there were many exceptions. However, the discovery of Verner’s Law showed that exceptions might just be apparent; sound change is still ‘regular and exceptionless’, you just have to look a bit closer for the regularities.
An example of one such ‘exception’ is father, from above.
Note how Latin pater (which retains the /p/ and /t/ from PIE) shows up as father in English. IE /p/ > Gmc /f/ as predicted by Grimm’s Law, but IE /t/ has not come out as /θ/ instead we find /ð/. More telling are examples of related words which have the predicted sound in some cases but not in others! For example, English birthandburden are both related but show different outcomes of what was historically the same consonant.
Karl Verner noticed, however, that the unpredictable instances correlated with the position of accent in PIE. Sanskrit retains much of the earlier accent system which Germanic has subsequently changed. Sanskrit pater retains the accent following the /t/. Verner noticed that Germanic results from Law A were voiced unless they were immediately preceded by an accented syllable (in which case they would be voiceless) – this is Verner’s Law. Subsequently many of these Germanic voiced fricatives became voiced stops (thus leading to birthandburden). Germanic also underwent an Accent Shift whereby the position of accent changed. This annihilated the conditions for Verner’s Law but left the results of it unchanged, i.e. the results went from being conditioned and predictable (phonetic) to unconditioned and unpredictable (phonemic).
Verner’s Law also helped to explain cases of /s/-/r/ alternations, so called rhotacism. That is /s/ was pronounced as [z] by Verner’s Law unless preceded by accent. This [z] sound then underwent rhotacism to become /r/. Old Latin shows flos-floris‘flower’, English shows was-were etc. Many of the results of Verner’s Law have, however, been lost through analogical levelling. Latin underwent levelling to yield flor-floris‘flower’ and many English dialects have levelled the was-wereparadigm (as has Modern German), i.e. you might hear people saying ‘we was, you was, they was’.
Verner’s Law was and is a fantastic example of how powerful the comparative method is when applied carefully and rigorously. It also gave a great confidence boost to the Neogrammarian Hypothesis which says that sound change is regular and exceptionless. But that is not the end of Verner’s Law…it’s still around in places. When you next come across execute and executor/executive, think carefully about where the stress falls and how you are pronouncing the <x> in those cases – you might just see Verner’s Law in action!
Grimm’s Law (also called the First Germanic Sound Shift) refers to changes which affected the stop consonants in what became the Germanic subgroup of the Indo-European language family (Proto-Germanic being the ancestor of all Germanic languages, i.e. Gothic, German, Yiddish, Swedish, Icelandic, Dutch, Afrikaans, Old English, English etc.). There are in fact three series of changes which changed some aspect of the articulation of the IE stop consonants whilst retaining the same number of distinctions (number of phonemes).
Law A: IE /p t k/ > Gmc /f θ x/
Law B: IE /b d g/ > Gmc /p t k/
Law C: IE /bh dh gh/ > Gmc /β ð γ/ (which later became /b d g/)
Exactly when this happened is not known but we can at least work when the Laws may have taken effect relative to each other, e.g. Law A cannot have happened after Law B because otherwise we would expect IE /b d g/ to show up as /f θ x/ in Germanic.
For example:
Latinpater > Englishfather, German Vater(German orthographic <v> is pronounced /f/)
Greektri > English three
Latincord- > English heart (English /h/ descends from earlier /x/)
Sanskritbhratar > English brother, German Bruder
These are standard but selective examples. Standard in the sense that you’ll find them in text books; selective in that we cannot simply look at one language and expect it to faithfully represent changes which happened hundreds of years ago. Latin, Greek and Sanskrit have undergone changes since Proto-Indo-European and English and German have undergone changes since Proto-Germanic. Modern German shows evidence of a Second Germanic Sound Shift which changed the Germanic stop consonants again! English did not undergo this change as it had already separated from the language that was to become German (compare threeanddrei,daughterandTochteretc.).
We don’t talk about Bruno, no, no, no! We don’t talk about Bruno… but
The more I play this song in my head, the more impressed I am with the rhyme schemes.
It was my weddingday It was our weddingday We were getting ready, and there wasn’t a cloud in the sky No clouds allowed in the sky
Bruno walks inwith a mischievous grin- Thunder!! You telling this story,oramI? I’m sorry, mi vida, go on
Bruno says, “Itlookslikerain” Why did he tell us? In doing so, he floodsmybrain Abuela, get the umbrellas Married in a hurricane What a joyous day… but anyway
We don’t talk about Bruno, no, no, no! We don’t talk about Bruno!
Pepa and Felix, aside from interrupting one another (Pepa’s side-eye!), get some nice internal and partial rhymes in: ‘wedding-getting-ready’, ‘clouds-allowed’. I love the that ‘umbrellas’ is rhymed with ‘he tell us’, and partly echoed in ‘Abuela’, and the sort of echo between ‘married’ and ‘hurricane’, while ‘looks like rain’ and ‘floods my brain’ plays on sound, rhyme and the watery imagery.
Hey!Grew to live in fearofBrunostutteringorstumbling I could always hearhim sort of mutteringandmumbling I associate him with the sound of falling sand, ch-ch-ch It’s a heavy lift, with a giftsohumbling AlwaysleftAbuela and the familyfumbling Grappling with prophecies they couldn’t understand Do you understand?
This bit of Dolores’ is wonderfully complex. ‘Fear-stuttering-stumbling’ and ‘hear-muttering-mumbling’ has rhyme and alliteration across and within lines. I also think ‘fear/hear’ is also dimly echoed by the ‘-ering’ in ‘stuttering/muttering’ because then a similar pattern is repeated with ‘lift-gift-humbling’ and ‘left-family-fumbling’. There’s some great assonance with ‘associate-sound-sand’, and then some partial alliteration with ‘grappling-prophecies’.
A seven-foot frame Rats along his back When he calls your name Itall fades to black Yeah, he sees your dreams And feastson your screams (hey!)
I’ve highlighted the stressed vowels in Camilo’s part. English spelling obscures some of the phonological patterns, but using a rough phonetic transcription, it’s perhaps easier to see the same vowels pop up over and over, with the high front vowel /i/ in ‘sees-dreams-feasts-screams’ building some tension at the end.
ɛ-ʊ-eɪ
a-ɔ-a
ɔ-ɔ-eɪ
ɔ-eɪ-a
i-ɔ-i
i-ɔ-i
We don’t talk about Bruno, no, no, no! (We don’t talk about Bruno, no, no, no!) We don’t talk about Bruno (we don’t talk about Bruno!)
He told me my fish would die The next day: dead! (No, no!) He told me I’d grow a gut! And just like he said… (no, no!) He said that all my hair would disappear, now look at my head (no, no! Hey!) Your fate is sealed when your prophecy is read!
Not much to say about the bit above - maybe that’s why Lin-Manuel Miranda gave it to the townsfolk!
He told me that the life of my dreams would be promised, and someday be mine He told me that my power would grow, like the grapes that thrive on the vine Óye, Mariano’s on his way
He told methat the man of my dreams would be just out of reach Betrothed to another It’s like I hear him now Hey sis, I wantnot a sound out of you (it’s like I can hear him now) I can hear him now
These two bits contrast with one another in the music itself, and mirror each other in the language. It’s neat that for Isabela’s line with ‘me-dreams-promised-someday’, the syllable with /m/ and/or /i/ is sung on a higher note that the surrounding syllables, while in the corresponding line for Dolores’ part ‘me-man-dreams-reach’, the /m/ and/or /i/ is generally on a lower note than the surrounding syllables. Then there is also some alliteration ‘grow-grapes’ and even ‘thrive-vine’, ‘betrothed-another’ and ‘want-not-sound’.
Rhyme scheme nerdfest over … for now. That’s what you get for talking about Bruno!
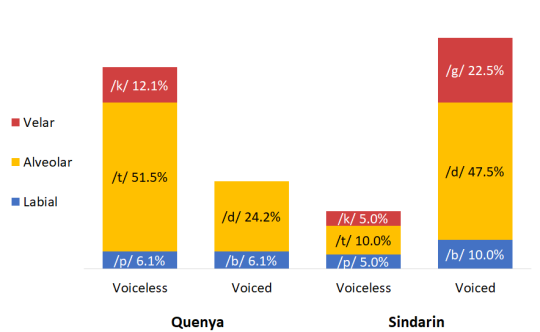
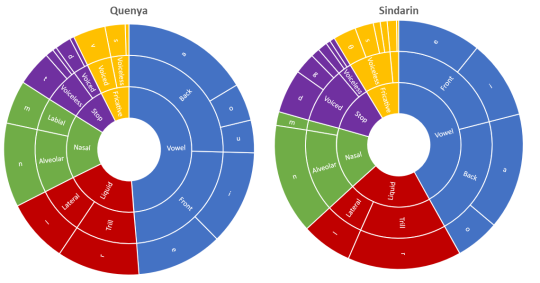
I recently wondered if there was a way to visualise some aspects of the phonological character of Quenya and Sindarin, and the differences between them. The following charts are based on the Namárië poem for Quenya and The King’s Letter for Sindarin. I did a broad phonological transcription for both, then ran frequency counts and relative frequencies on the phonemes. And here are some of the results!
1. Tolkien liked his alveolar stops! And whilst Quenya shows a preference for voiceless stops over voiced stops, the reverse is true of Sindarin.
Part of the reason why the Sindarin voiced stops are so prevalent is due to the extensive consonant mutation system of Sindarin. In the case of stop consonants, the soft mutation turns voiceless stops into voiced stops in certain phonological and/or grammatical environments.
2. Both Quenya and Sindarin prefer front vowels over back vowels, i.e. /i/ and /e/ are preferred over /u/ and /o/ (the Sindarin text happened not to have /u/ at all). The low vowel /ɑ/ is the most frequent vowel in both languages.
Tolkien wrote that in Quenya, the vowel sign for /ɑ/ was often left out in writing, e.g. calma ‘lamp’ could be written as clm (using the equivalent Elvish characters, of course!).
3. Quenya seems to be more vowel-heavy than Sindarin, but Sindarin’s consonants seem to have a larger proportion of liquids, nasals and fricatives … and Sindarin /n/ and /r/ are super-popular!
Almost half of the phonemes shown for Quenya are vowels, compared with two-fifths in Sindarin. As Tolkien wrote, Quenya words more often ended in a vowel, whilst those in Sindarin more often ended in a consonant.
In Sindarin, about two in seven phonemes (of those shown in the chart) is either /r/ or /n/! In Quenya, /n/ appears about twice as often as /m/, but in Sindarin, /n/ appears about seven times more often than /m/!
Aspirations occurs in English in initial onsets like in ‘pat’ [pʰæt], ‘tack’ [’tʰæk] or ‘cat’ [’kʰæt]. It is not phonemic, since it doesn’t distinguish meanings, but it’s distinctive in Mandarin e.g. 皮 [pʰi] (skin) vs. 比 [pi] (proportion).
Languages that have a phonemic glottal stop /ʔ/ - about 40% of all human languages. This is a very widespread consonant except in Indo-European, Niger-Congo, Turkic, Uralic, Mongolic, Dravidian, Koreanic and Japonic languages.
It’s almost universally present in the indigenous languages of the Americas, in Afro-Asiatic languages, in Austroasiatic and Austronesian languages, in Papuan languages, North Caucasian langauges, and in some Khoe, Sino-Tibetan, Daic, Uralic, Iranian, Turkic and Chukotko-Kamchatkan languages. It’s also present in Estuary and Scouse English as in ‘watter’ as /woːʔɐ/.
This is the vowel used in English “sad”. It exists as an allophone of other vowels in Turkish, Russian, Dutch, Slovak, Swedish and French (as a nasal vowel).
Phonemically, it exists in English, all Arabic languages/dialects, all Berber languages, Somali, Afrikaans, Norwegian, Finnish, Estonian, Latvian, Lithuanian, Danish, Kurdish, Azeri, Persian, Qazaq, Uzbek, Turkmen, Uyghur, Bashkir, Orya, Sinhalese, and in some dialects of Portuguese, Andalusian Spanish, Greek, Romanian.
One of the interesting linguistic effects of the internet is that sound changes can propagate regardless of geography – like, I’m seeing Australians on Youtube who have GenAm æ-breaking
Notregardless of geography, I bet - these YouTubers are regularly co-producing videos with, talking to, and visiting Americans, I’m guessing? I don’t want to launch into my whole spiel about how there’s no evidence that mass media has caused any changes in the phonology of English dialects, so I’ll just say I greatly doubt, based on what we’ve seen in the 140 years since the invention of artificial sound reproduction, that anyone will be picking up an American accent from passively watching YouTube videos.
And I don’t remember where I read it, but it’s apparently a principle, based on an appeal to Occam’s Razor, in at least some circles of historical linguistics that internal explanations should always be sought first before looking to contact - and it is true that /æ/ is historically unstable in English. Could it simply be that some Australians have independently started breaking /æ/, and some of them happen to be YouTubers?
Also, Youtube is an international medium - a person who posts videos on Youtube is intentionally seeking to communicate with people outside of their local community or even their country. So, it may well be that they’re consciously adopting American pronunciations specifically in the context of producing Youtube videos.
When talking to their local friends and neighbors, it’s quite possible that they don’t have those Americanized pronunciations. Their Youtube videos are likely a biased sample of their speech.
“Catching weary waterfowl on thin ice gives surly polar bears huge pleasure and ensures they enjoy good meat unharmed.”
—
A panphone (sentence that contains every phoneme in the English language, at least for the composer’s dialect) by Richard Gunton on Literal Minded. You may need to adjust slightly for your own dialect, but the post about it provides an interesting place to start.
(Compare with pangrams, i.e. sentences that contain every letter in a given alphabet.)
In Doctor Strange and the Multiverse of Madness, the character America Chavez is played by Xochitl Gomez
When I checked the IPA pronunciation of her name in English, I almost fell off my chair. Her name is obviously of Nahuatlorigin, it means “flower”. It is pronounced /ʃoː.tʃitɬ/inNahuatl. Then her name in Spanishbecomes/ˈso.t͡ʃitl/ and ends up as /ˈsoʊ.tʃi/inAmerican English and I honestly can’t forgive it
To note, /ˈʃo.t͡ʃitl/ also exists in Spanish, but might not be the norm, given that the language doesn’t have /ʃ/ in word-initial position in its native lexicon and is “normalised” to /s/ but can be kept there in Spanish varieties that have long been in contact with languages that do admit an initial /ʃ/likeNahuatl
Are there examples from outside the Sichuan/Yunnan/Tibet area of the development of postocclusion, as in ɬ ɮ > ɬtʰ ɮd? Is this even diachronically correct, or is postocclusion here a retention after a development of e.g. *l.t- > ɬᵗ?
Examples of “suffricates” as an etymologically single segment aren’t exactly common in general of course. At least Bulgarian / Old Church Slavonic *ť *ď > št žd and (some?) Ancient Greek *ď > †zd are diachronically clear cases. If Sino-Caucasianists are on to anything, Burushaski has t-:-lt- from earlier *tɬ. None of these, though, come from a fricative. So yes maybe suggestions of earlier *ɬ *ɮ are indeed simply incorrect and should be rather *lt- *ld- or *tl- *dl- or *tɬ- *dɮ-. The development of Written Tibetan zl- to some varieties’ /ld-/ might then be simply routed as fortition to *dl (additionally via *zdl if wanted) plus metathesis. Per Hill (2011: 446) this metathesis has been already proposed long since by Simon in 1929. Or maybe that should be rather Proto-Tibetic *zl-, since this metathesis seems to precede WT!
Tangentially on the topic, Awngi has notably been described as having /s͡t ʃ͡t/, similar to affricates in occurring at syllable boundaries even word-internally. They also fail to be ever broken up by epenthetic [ɨ], but at least this argument is not followed consistently: other homorganic clusters like /mb/ or /rt/ are tolerated within a syllable too; moreover, both the “prestopped fricatives” and certain “tolerated clusters” trigger epenthesis of initial [ɨ]. There does not seem to be evidence for an earlier monophonemic origin. It looks to me that allowing minor complication in syllable structure (existence of some cases of -CC.C- not epenthesized to -CCɨC- or -CɨCC-) would be a better analysis than positing fairly exceptional contour consonants, which brings to my mind the weird Africanist style of analyses that sometimes suggest even clusters like /kɾ/ to be “single consonants”.
For that matter, a strictly epenthetic nature of [ɨ] is not tenable for modern-day Awngi anyway: this analysis is originally due to Joswig, who however admits that it is (1) not followed by loanwords from Amharic, (2) not followed by the native noun [sɨsqi] ‘sweat’ (**[ɨssɨqi]), (3) bled by a proposed degemination of a variety of consonants. All these problems would seem to be solved by treating epenthesis of /ɨ/ as a historical sound change and not a synchronic process.
Differing regular reflexes like *q > k or *q > ʔ establish that this must have remained as its own segment as late as until Proto-Oceanic and various other great-grand-daughter groups. Yet, out of a four-digit number of descendants, there are no more than two languages outside of Taiwan that have a /q/ that seems to come from *q (even one of them, upon reanalysis, apparently instead first merging *k and *q and then backing this *k to /q/ in various environments). Worldwide, uvulars are not all that rare, found in about 20% of languages. So Austronesian is off from the world average here by a factor of 100!
After rejecting a few other hypotheses involving e.g. functional load or language contact effects, Blevins settles on a hypothesis of conditional in/stability of uvulars, which sounds believable to me:
A more relevant structural factor that appears to be strongly correlated with /q/ versus /k/ contrasts is the size and shape of the vowel system. In language families like Semitic, Quechuan, and Eskimo–Aleut (aka Inuit–Yupik- Unangan), where uvular versus velar stop contrasts are reconstructable to the proto-language, and continued robustly, reconstructed vowel systems are small, and are also continued in most daughter languages (…) One possible explanation for the association between small peripheral vowel systems and velar versus uvular stop contrasts relates to perceptual cues of uvulars on adjacent vowels: uvulars are often described with significant “lowering” and “backing” effects on neighboring vowels, so that /i/ might be heard as [e], or /u/ as [o] before a uvular (…) in five vowel systems like /i u e o a/, lowering effects of uvulars would be less salient, or could be mistaken for intrinsic vowel properties.
This checks out also within Austronesian:
The PAN vowel system, as we have seen, was one with three peripheral vowels *i, *u, *a, and one central vowel, *ə. Interestingly, the Formosan languages that show uvular reflexes of *q are precisely those that have either retained the PAN four-vowel system or reduced it further to a three-vowel system with /i u a/.
[B]y PCEMP the vowel system had expanded to *i, *u, *e, *o, *a, *ə (with five peripheral vowels), later reduced to *i, *u, *e, *o, *a in Proto-South Halmahera–West New Guinea and POC (Blust 1993:247). If the *q versus *k contrast was dependent on pho- netic cues that were best realized in a vowel system with /i, u, a, (ə)/, then the expansion of the PCEMP vowel system might be seen as an important structural factor determining a drift away from /q/ in all descendant languages.
I can add that the languages I know with uvulars + large vowel systems (Siberian Uralic and various adjacent Turkic) seem to keep tight reins on the co-occurrence of uvulars and different vowels, often maintaining [q] as a mere “syllable harmonic” allophone of /k/ before back vowels. The case of Northern Khanty and Northern Mansi is also interesting, with a major vowel system collapse leading to a well-loaded /k/ : /χ/ (< *q) contrast. We find generally smallish vowel inventories plus robust uvular inventories also in e.g. NW Caucasian and more northern parts of Na-Dene; also Proto-Indo-European if the “plain velars” were treated as uvulars. Kartvelian might count as an example of sorts of this instability of uvulars, showing vowel systems with 5 or more members + original *q merging with /x/ in 3 languages out of 4. (/qʼ/ remains stable though; and it is also noted by Blevins that languages that have uvulars are also more likely to have ejectives.)
Counterexamples do still exist. NE Caucasian, at least, is a decently large family with sometimes quite large vowel systems and universally maintaining a large stock of uvulars. Cushitic languages also tend to have at least all of basic /a e i o u/ even when having uvulars (be they Awngi or Iraqw or Somali). But then most do not have them, and we could also consider /q/ rather than /kʼ/ being recent rub-off from Arabic in many of them.
—
There is one possible hypothesis that seems to me to have escaped consideration, though: intermediate development? Perhaps, in some major intermediate languages like Proto-Oceanic, *q had changed to a reflex that was no longer a uvular stop but also not yet any of the most common reflexes — for example, an epiglottal stop *ʡ (attested as a reflex of *q in Amis) or a voiceless uvular fricative *χ, that probably should be expected to often decay to various glottal consonants or zero, but maybe could be still also sometimes re-fronted to reflexes like a velar stop /k/ or a velar fricative /ɣ/. Are there any areal tendencies in the frequency of velar (fronted) versus glottal etc. (backed) reflexes of *q across Austronesian? If yes, that might be a point in favor of this explanation.






![Aspirated plosivesAspirations occurs in English in initial onsets like in ‘pat’ [pʰæt], ‘tack’ [’tʰæ](https://64.media.tumblr.com/336a13765fb031784e1593639b0bb427/49a2b1dfe50b20fa-60/s1280x1920/bacfce7c8a594925b494a66a1177334d9a84edb7.png "Aspirated plosivesAspirations occurs in English in initial onsets like in ‘pat’ [pʰæt], ‘tack’ [’tʰæ")

 Open/low front unrounded vowelThis is the vowel used in English “sad”. It exists as an allop")






